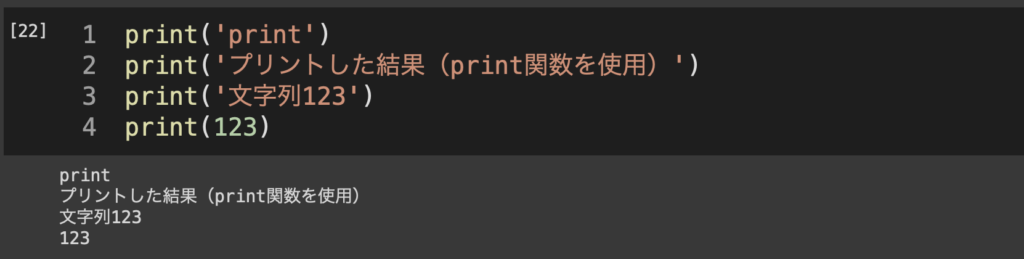
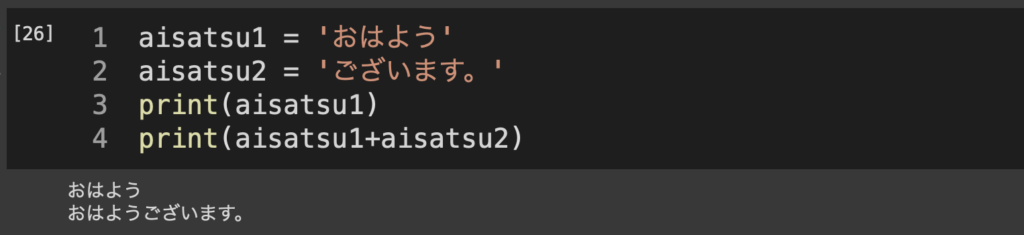
Python超基礎1:変数型と変数化 今回はインターネット環境さえあれば誰でも簡単にプログラミング言語Python(パイソン)を用いて解析を行うことができるGoogle Colaboratory(コラボラトリー, Colab)を利用した解析例を示す。(使用にはGoogleアカウントでのログインが必要だが、名城生はメイネットIDを用いたシングルサインオンで利用できる) 今回の実習では実際のID-POSを元に作成したシミュレーション用の擬似データを用いる。対象品目はコーヒーとして、スーパーマーケットで購買されたものである。今回は分析のしやすさを高める目的でサンプルを大幅に絞っており、ある程度頻繁に購入している消費者のみを対象とした。 0. Colabにアクセスする まずはColaboratoryにアクセスする。 右上からGoogleアカウントでログインしたら、左上[ファイル]から「Python 3の新しいノートブック」を選択して空のプロジェクトを作成する。 Colaboratoryではセルと呼ばれるブロックごとにプログラムを実行し結果を確認することができるようになっている(以下の画像はダークモードの画面になっているが、得られる結果など動作は一般のものと同様)。 とりあえず何も考えず、試しに2+3と入力して実行(左側の再生ボタンを押すかShift+Enter)すると… 結果(2+3の計算結果としての5)が出力される。これでブロックごとにやりたい分析や処理を書き進めていく。 1. Python超基礎1: 変数型と変数化 まず理解しなけrばいけないこととして、Pythonに入力できる情報には「型」(タイプ)が存在しており、それぞれで処理できることが異なる。初歩的なものだけ紹介しておく。 1.1 数値型(int, float) これは文字通り、数値情報を扱える変数型で、整数はint型、小数点を含む浮動小数のfloat型、他に複素数を扱うcomplex型もありますが、授業で扱うレベルの内容では自動で最適なものが割り当てられるため特に意識する必要はありません。 たとえばあるオブジェクトの変数型を調べるtype()関数に整数12345と小数123.45を投入すると、 このようにそれぞれint, floatと最適な変数型で入力されていることがわかる。 数値型では 1+2, 4/2, 2*3のような演算処理を行える。 Colabでは一番下の行に入力されたもの以外は結果が表示されないので、print()関数を使って表示させています。 その他に、あまり見慣れなさそうなものとして「比較」を紹介しておくと、 命題「100は10以上である」に対してTrue(真) 命題「3は1未満である」に対してFalse(偽) 命題「25と25.00は同一である」に対してTrue(真) 命題「7と5は異なっている」に対してTrue(真) というように、2つのオブジェクトを「比較演算子」でつなぐことでそれら2つを比較した結果が返される。 print(2+3) # 和 print(3-1) # 差 print(5*2) # 積 print(1/25) # 商 print(100 >= 10) print(3 < 1) print(25 == 25.00) print(7 != 5) 1.2 文字型(str) 次に文字型(正確にはテキストシーケンス型)について。 ここまでprintという関数を用いて結果を表示させるようなことも紹介した。これは数値型をprintするだけだったので特に意識する必要はなかったが、ではprintという文字列をprintするにはどうすればいいだろうか? たとえばprint(print)とすると、 と表示されているが、これはprint()関数に関する情報(Pythonの組み込み関数であるprint)が表示されているに過ぎない。つまりPythonに文字列を読み込ませるには、それがただの文字列であることを明示的に指定しなければならないというわけだ。これには”クォーテーション”を用いる。 見て分かる通り、アルファベットだけでなく数字・日本語・記号もクォーテーションで囲むことでstrオブジェクトとして扱いprint等に投入することができるようになる。 1.3 変数化 ある情報の入力にあたり、それをそのまま用いずに「変数」として定義することもできる。 これはaに2を、bに3という数字を割り当てた状態で、a×bの計算結果を表示させたもの。 あるいは文字列でも、そして変数名をもう少し長くしても このような形で処理できる。ここでstr同士の+(aisatsu1+aisatsu2)は文字列の「結合」を意味している。 ここまでだと正直変数化のメリットは対して感じられないかもしれない。 1.4 datetime型 datetime型はその名の通り、日付と時刻を扱うためのデータ型である。ただし、datetimeはPythonを立ち上げた初期状態では動作しないようになっている。ここでは追加で「datetimeパッケージ」を読み込んだ上でその機能を用いていく。パッケージの読み込みにはimportを使う。 こうすることで、datetimeパッケージの中に含まれている関数をdatetime.***という形で利用できるようになる。たとえばtimezone関数ならdatetime.timezone()など。今回は(わかりにくくて申し訳ないが)datetimeパッケージ内のdatetime関数を用いる。 datetime関数では順番に年月日時分秒を指定することで、ある日付時刻を設定できる。 これはたとえば2時点をそれぞれstart、endという名前で変数化してその差を取ると、 23日と37800秒離れていることがわかる。 他の章へ飛ぶ Python超基礎1:変数型と変数化 Python超基礎2:ColabとGoogle Driveの連携 Python超基礎3:データの読み込みと基本操作 Python超基礎4:データの集計 Python超基礎5:データの図示 Python超基礎6:条件抽出 Python超基礎7:ループ処理 メニュー Python超基礎1:変数型と変数化 Python超基礎2:ColabとGoogle Driveの連携 Python超基礎3:データの読み込みと基本操作 Python超基礎4:データの集計 Python超基礎5:データの図示 Python超基礎6:条件抽出 Python超基礎7:ループ処理