

ここからは実際にデータを読み込み、それを集計することを考える。
3. データの読み込みと基本操作
3.1 追加パッケージのインストールと読み込み
まずは分析に先立って、分析に必要なパッケージの読み込みを行う。
プログラミング言語としてのPythonで開発された機能以外にも、第三者がPythonで使用できる機能を開発して「パッケージ」としてまとめたものが提供されている。今回はデータを整理して表示するためによく使われているpandas(pandas-dev/pandas)、そして次回グラフでデータを図示するにあたり、簡単に日本語を表示できるようにするjapanize-matplotlib(uehara1414/japanize-matplotlib)を使用する。
pandasは既にColab上にインストールされている。そういった既にインストール済みのパッケージでもその数は膨大であるため、「インポート」することで必要なものだけが使用できるようになる。
たとえばpandasの場合なら
import pandas as pd
の形で読み込むことができる。これはpandasというパッケージをpdという名前として(=as pd)インポートすることを意味している(pandasは慣習的にpdという略称で呼び出されることが多い)。これにより、今後pandasパッケージに含まれる機能は「pd.****」で呼び出すことができるようになる。
一方のjapanize_matplotlibはデフォルトではColabに含まれていないので、新しいセルを作成して
%pip install japanize_matplotlib
を実行することでインストールできる。
このようにインストールのプロセスが進行し、最後に”Successfully installed japanize-matplotlib-X.X.X”が表示されればOK(1.1.3はバージョンなので数字が異なっていてもOK)。
ちなみにこの%から始まるコマンドはColab上ではマジックコマンド(Magic Commands)と呼ばれている。詳しくは省略するが、マジックコマンドやシステムコマンドなどの機能はPythonの機能ではなく、より上位のレイヤー(Pythonが動作しているシステム自体)に作用するコマンドをColab上から実行できるようなイメージで考えておけばいい。
インストールされたら同様にインポートすればいい。
import japanize_matplotlib
このパッケージはインポートするだけで自動的に機能するので設定は不要。
3.2 データの読み込み
指定された授業フォルダ(たとえばMRes2021-共有)までたどり着いたら、開きたいファイルを選んで、ファイル名の右横の三点のボタンを押すと、「ダウンロード」や「ファイル名の変更」と並んで「パスをコピー」というボタンがあるのでこれを選択。
今回は「MRes2021-共有」内に入れてあるpos2021.pklというファイルを読み出すことにする。この拡張子pklで保存されているPickleファイルは、Pythonにおいてデータを直列化(Serialize)したもので、非常に簡単にいうとデータの細かい情報までを保持した状態でファイルに落とし込んだもの。
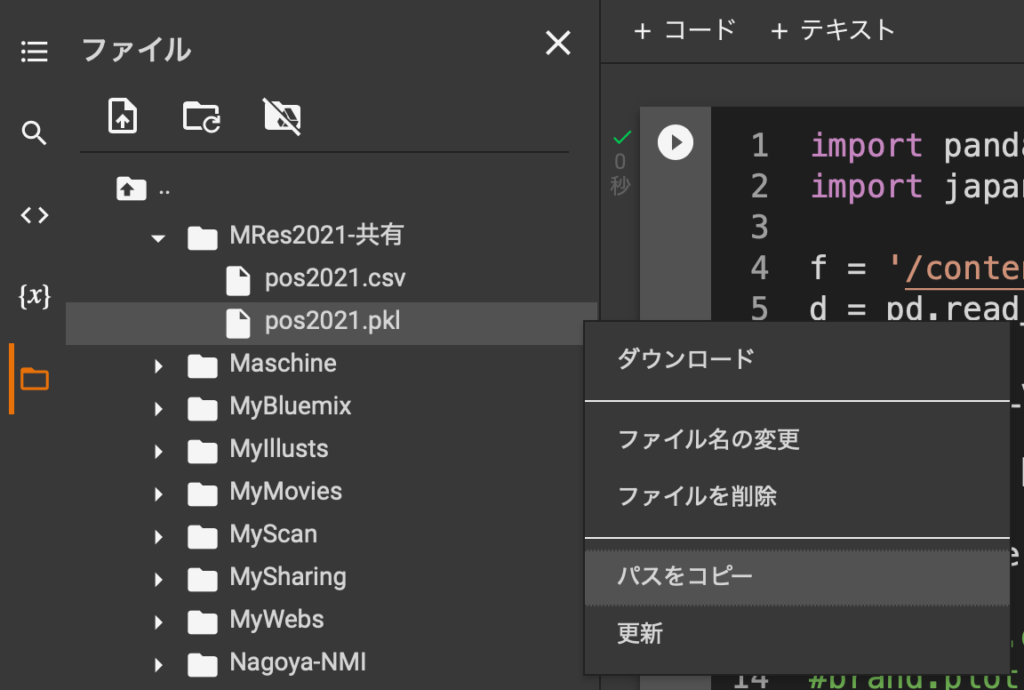
これでそのファイルまでの「場所」がわかったので、それを読み込むべきファイルの場所として指定する。今回はファイルの場所を示す変数「f」と、それを読み込んだデータセット「d」を作ることにする。僕の授業の履修者は授業の指示に従ってGoogle Drive上の共有フォルダを前回の内容に従ってマイドライブに追加しておけば、上の場所でファイルの読み込みができる。
f = '/content/drive/MyDrive/MRes2021-共有/pos2021.pkl'
ちなみにこれはシミュレーションで作成したダミーデータのため、履修者以外、あるいは一般の方向けにGitHub上でも公開しますので、必要であれば以下のファイルパスで読み込んでください。
f = 'https://github.com/jniimi/data-pool/blob/main/Marketing_Research/pos2021.pkl?raw=true'
ファイルの場所を示す変数「f」は文字列の変数(より正確にはstr型)なので、クオーテーションで囲むことにより、これが文字を表しているのだということを教えてあげる必要がある(本来であればファイルを開くにはwith open等ある方がいいが今回は割愛)。
このファイルは拡張子を見ればわかるように.pkl(pickleファイル)となっており、Excelなどの一般的な表計算ソフトで開ける形式ではない。それもそのはずで、このpickleファイルはPythonでデータ等を直列化(簡単にいうとデータをその複雑な構造や保持している細かい情報を毀損することなく単純な構造に変換する方法)して保存したものなので、基本的にはPythonで開くことが想定されているためだ。
これを開くには色々な方法があるが、今回はpandasのread_pickle関数を使う。
d = pd.read_pickle(f)
これはつまり、pandasパッケージ内に含まれた関数であるread_pickleにf(=pickleファイルの場所)を教えることでデータを読み込み、そのデータをdという名前で定義したことを意味する。
ちなみにpandasでは、pickleファイル以外にもread_csvなどの関数を用いることで、一般的なcsv形式のデータなども読み込み可能。ちなみに、あまりお勧めはしないがExcelファイルを直接読み出せるread_excel関数も存在する。
これまで数値や文字列をprint関数で表示させてきたが、こういったpandasのデータ(正確にはDataFrame=データフレーム, 通称df)を表示させる場合にはdisplay関数を用いるとより綺麗に表示される。
display(d)
そのまま、dという名前のデータフレームを表示させるのでdisplay(d)。
↓ここまでの操作をColabでやるとこんな感じ↓
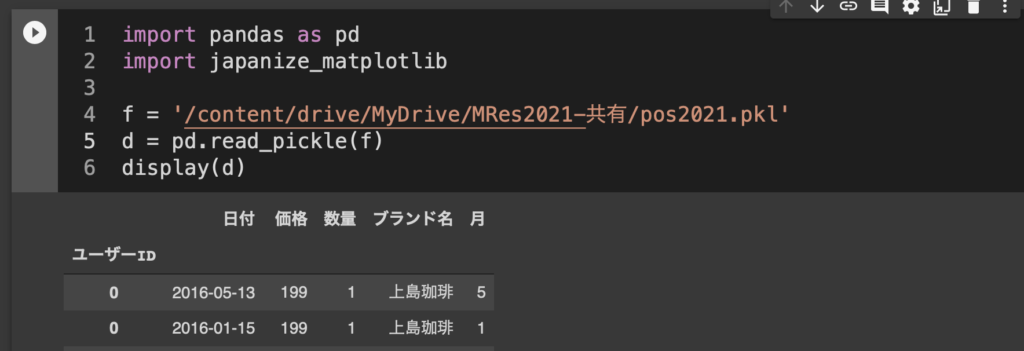
主な変数
- ユーザーID:このスーパーマーケットの顧客のうち、ポイントカードを持っている顧客に振られた固有の番号(=いわゆるお客様番号のような)
- 日付:購入された日付(YYYY-MM-DD)
- ブランド名:今回分析の対象としているコーヒーのブランド。
- 数量:その1回の購買で購入された商品の数量。
- 価格:その商品1点あたりの価格。
3.3 pandasの基本
これでデータを読み込んで表示することができた。ここから色々なことをやっていくわけだが、その前に基本的なデータの操作についてまとめておく。
まずは最も基本的なところとして、例示しているデータでは今5個の変数が含まれているが、その中のある変数1つを選択するにはブラケット(角カッコ)を用いて以下のようにする。
d['価格']
これはdのうち価格のみを選択した状態であることを示す。既にdの中に存在している変数ならこの形でもちろん選択できるし、もしdにまだ含まれていない変数なのであれば、簡単に新しい変数を作成することもできる。
たとえば単価と数量がわかっているので、そこからある商品の一回あたりの購買金額の合計を算出するなら、
d['合計金額'] = d['価格'] * d['数量']
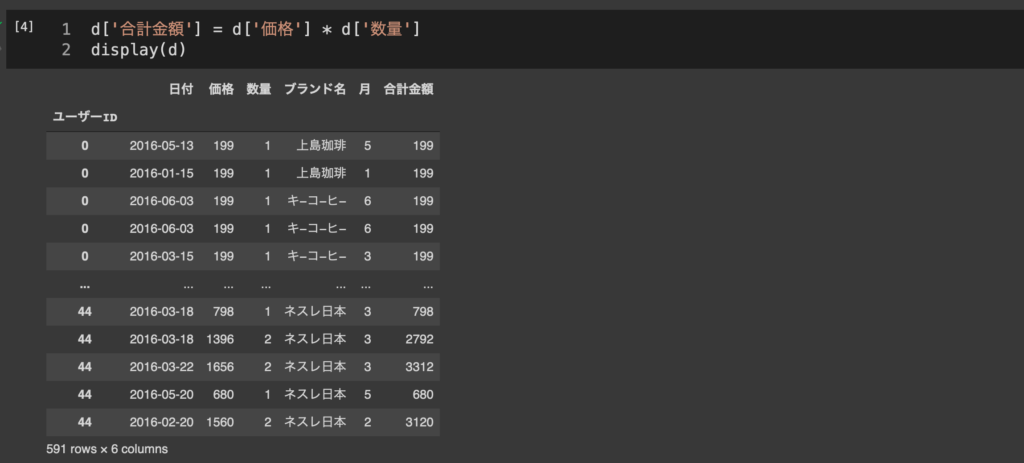
で作成できる。
ただし、既にdの中に合計金額という変数が存在している状態でこのコードを実行すると、既存の合計金額の変数をd[‘価格’] * d[‘数量’]の値で上書きしてしまうことに注意。