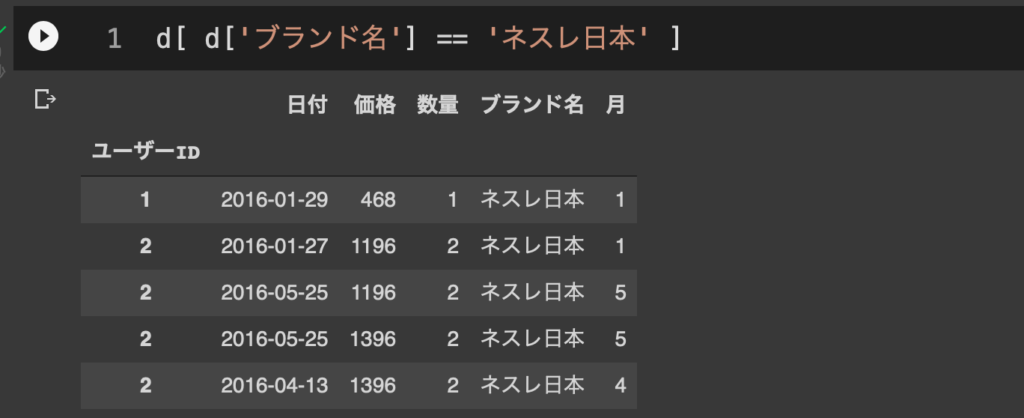
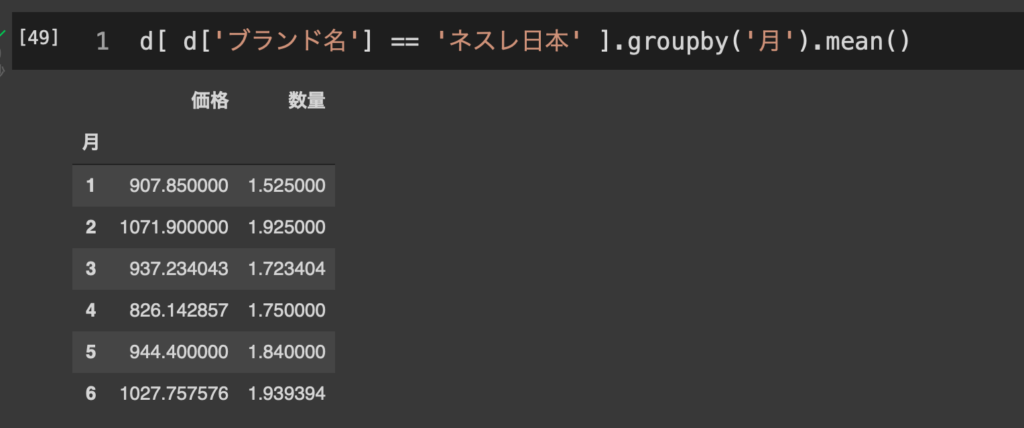
Python超基礎6:条件抽出 これまではデータ全体を対象にグループに分けるなどしながら分析をしてきたが、ここからはある条件にマッチしたデータのみを抽出することを考える。 7. 条件抽出 ここまでは、データセットdに含まれる全てのサンプルを用いて解析や図示を行ってきた。しかし、特定の条件に沿ったサンプルのみを対象としたい場合もある。こういった場合に用いられるのが条件抽出である。 条件抽出はデータセットdに対して d[ <条件式> ] の形で指定する。たとえばブランド名がネスレ日本であるサンプルのみを取り出すことを考えると、まずその条件式は比較演算子を使って d['ブランド名'] == 'ネスレ日本' となる。ここで==(イコールがふたつ)となっているのは前後の値が一致しているかどうか(言い換えるなら「ブランド名」という変数の中身が「ネスレ日本」という値になっているかどうか)を確認するための演算子(演算のための記号)を表す。 よってネスレ日本のサンプルのみを抽出するのであれば、 d[ d['ブランド名'] == 'ネスレ日本' ] となる(初学者にわかりやすいよう多めにスペースを入れている)。 これで抽出された新しいデータセット(通常は「サブセット」と呼ぶ)をさらに月次で集計するとしても、これもこれまでと同様ただ数珠つなぎにすればいい。 例えばブランドをネスレ日本に絞った上で月毎の平均売上を確認するとすれば、 d[ d['ブランド名'] == 'ネスレ日本' ].groupby('月').mean() などで可能。 慣れてくるとかなりシンプルな記述でそれなりに込み入った集計までできるようになる。 他の章へ飛ぶ Python超基礎1:変数型と変数化 Python超基礎2:ColabとGoogle Driveの連携 Python超基礎3:データの読み込みと基本操作 Python超基礎4:データの集計 Python超基礎5:データの図示 Python超基礎6:条件抽出 Python超基礎7:ループ処理 メニュー Python超基礎1:変数型と変数化 Python超基礎2:ColabとGoogle Driveの連携 Python超基礎3:データの読み込みと基本操作 Python超基礎4:データの集計 Python超基礎5:データの図示 Python超基礎6:条件抽出 Python超基礎7:ループ処理