

僕は最近acceptされたマルチモーダルモデルやら来月あたりpreprintに投げるつもりのBERT使ったモデルなど、ここしばらくのモデル比較をほぼ全部Weights & Biases (W&B) +kerasで管理しており、気づけばすっかりW&Bのヘヴィユーザーになってしまった。ただ、一方で僕は統計的な指標開発のためにかなりシンプルな線形回帰なんかでも論文を書く人なので、statsmodelsの解析結果も管理できるとありがたい。ということでちょっとやってみる。
準備
まあともかく準備である。Colabならwandbをpipで入れた上で必要なものを読み込みつつwandbのログインを済ませておく。僕が必要なのは大体この辺(普段は厳密にはstatsmodelsをベースとした自作パッケージを使ってるんだけど)。
!pip install -q wandb
import numpy as np
import pandas as pd
import statsmodels.api as sm
import wandb
wandb.login()
データ生成
正直なところ今回は回帰がしたいだけなのでデータはなんでもいい。適当にサンプルデータを作る。
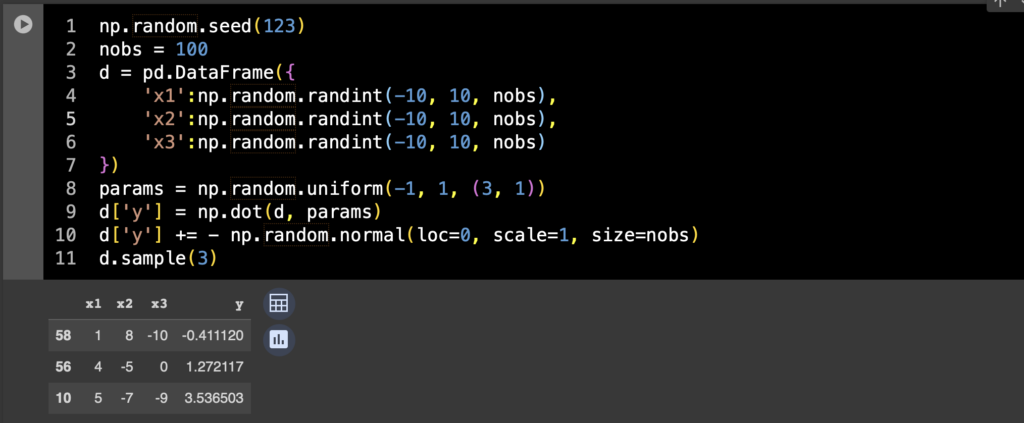
np.random.seed(123)
nobs = 100
d = pd.DataFrame({
'x1':np.random.randint(-10, 10, nobs),
'x2':np.random.randint(-10, 10, nobs),
'x3':np.random.randint(-10, 10, nobs)
})
params = np.random.uniform(-1, 1, (3, 1))
d['y'] = np.dot(d, params)
d['y'] += - np.random.normal(loc=0, scale=1, size=nobs)
d.sample(3)
一旦普通に回帰してみる
んでこれをstatsmodelsのOLSで普通に回帰するなら、
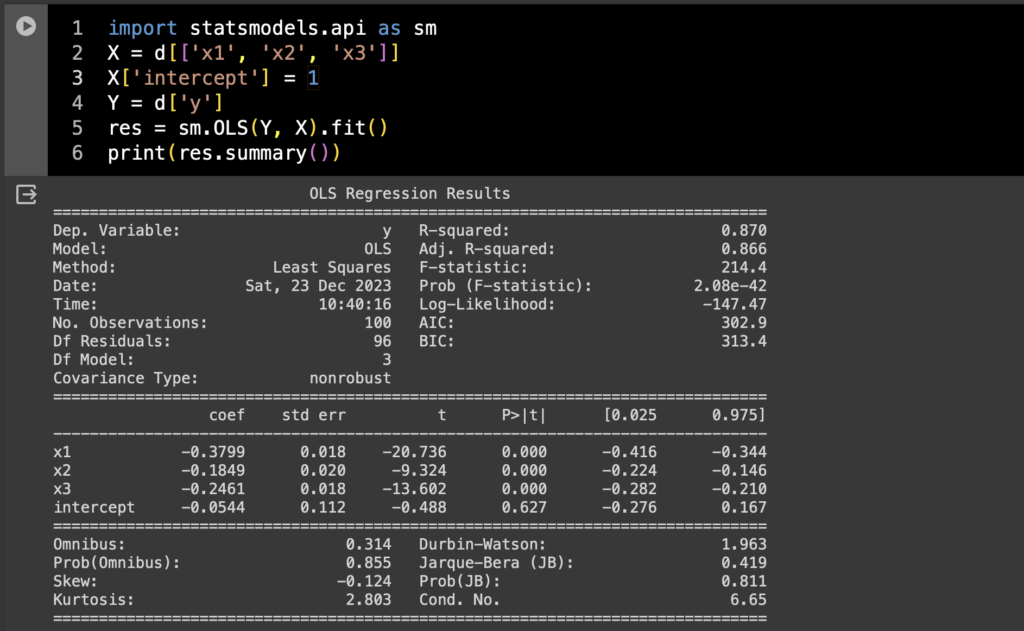
import statsmodels.api as sm
X = d[['x1', 'x2', 'x3']]
X['intercept'] = 1
Y = d['y']
res = sm.OLS(Y, X).fit()
print(res.summary())
まあこんなもんかな。この回帰の諸々をW&Bで管理できるようにしたい。
とりあえず関数化する
僕は何かにつけすぐ関数化したがるので今回も関数化する。
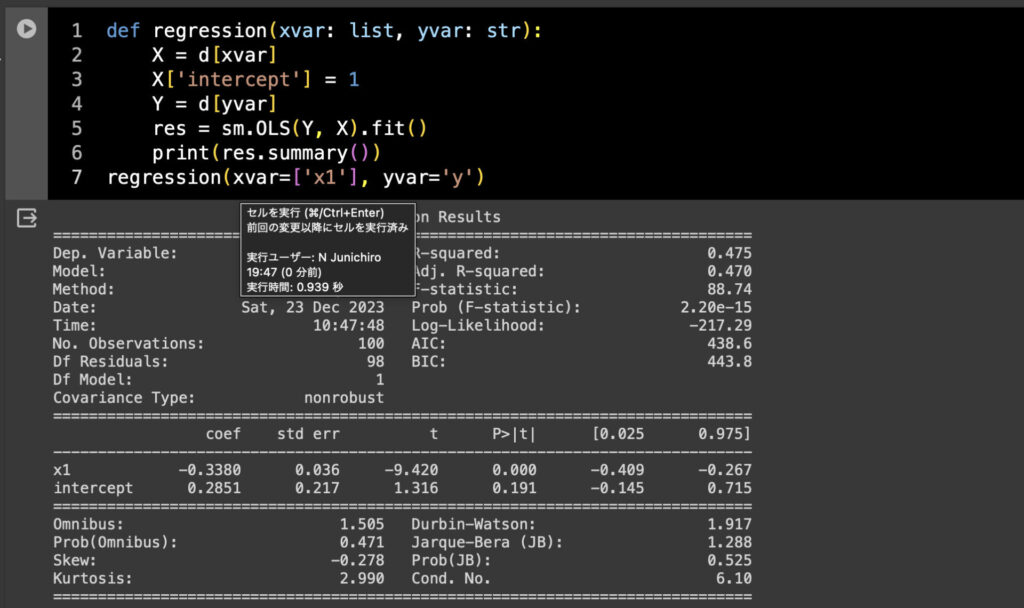
def regression(xvar: list, yvar: str):
X = d[xvar]
X['intercept'] = 1
Y = d[yvar]
res = sm.OLS(Y, X).fit()
print(res.summary())
regression(xvar=['x1'], yvar='y')
まあこんなもんでしょ。説明変数に使いたい変数リストとかを指定すると回帰が走るだけの簡単な関数。
W&Bの組み込み
あとは関数から投げられた引数をconfigに取ったwandb.run()を作りつつ、解析が終わったら必要な値を取ってくる。解析中あるいは解析後の情報は基本的にrun.log()にdictで与えてあげればいいので、
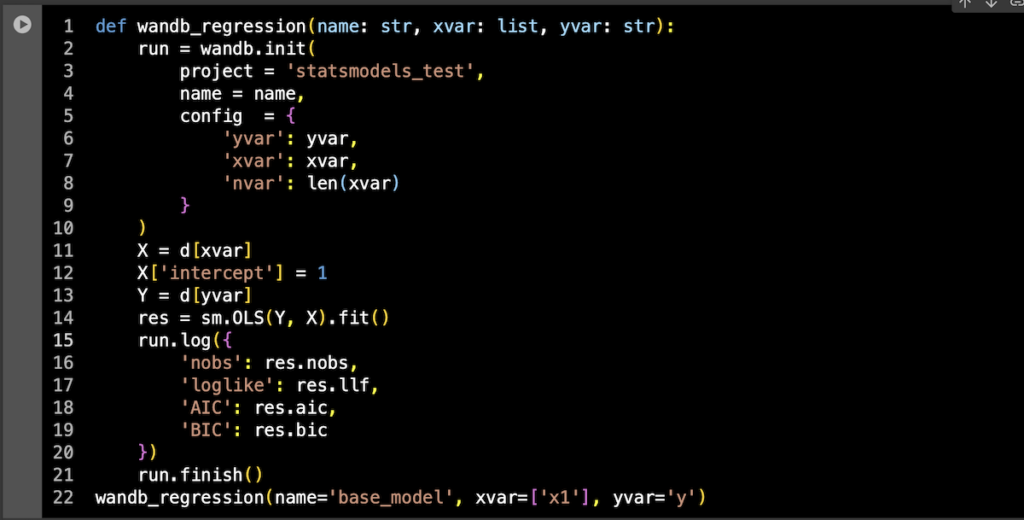
def wandb_regression(name: str, xvar: list, yvar: str):
run = wandb.init(
project = 'statsmodels_test',
name = name,
config = {
'yvar': yvar,
'xvar': xvar,
'nvar': len(xvar)
}
)
X = d[xvar]
X['intercept'] = 1
Y = d[yvar]
res = sm.OLS(Y, X).fit()
run.log({
'nobs': res.nobs,
'loglike': res.llf,
'AIC': res.aic,
'BIC': res.bic
})
run.finish()
wandb_regression(name='base_model', xvar=['x1'], yvar='y')
あとは各変数のパラメータ推定値やp-valueも持っておきたいので、

for key in res.params.keys():
run.log({
'param_'+key: res.params[key],
'pvalue_'+key: res.pvalues[key]
})
とりあえずはこんな感じで変数ごとに保管してあげればいいかなと思っている。Deep Learningのトレーニングのときみたいにステップごとの可視化がいらないので楽ですね。
W&B上で見てみる
いくつか変数を差し替えたパターンを実行した上で、W&B上でAICとBICの値を比較してみる。BIC by nvarは説明変数の数によるBICの平均。グループ平均を表示させたくてやってみたものの、正直なところBICの平均なんて見るべきではない。
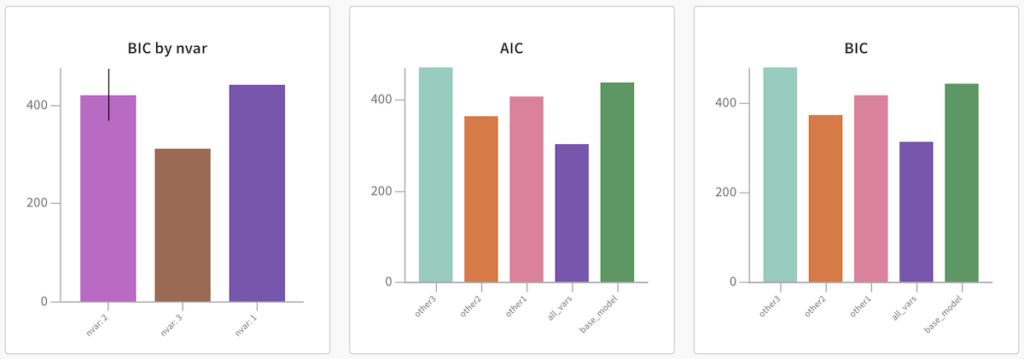
はい便利〜。
今まではモデル比較のためにこの辺の数値を片っ端からぜんぶpd.DataFrameで一つに統合してたんだけど、あの作業がバカに思えるほど楽ですね。まあもちろん(こと統計解析に関しては)ちゃんと結果を示すためにはもう少し踏み込んで色々パラメータの比較なんかもしなきゃいけないから、ちゃんと使うには一通りの解析が終わった後にW&Bからrunを全て呼び出したりする必要はあると思うけど、とはいえ下手したらモデルそれ自体をpickle化してそのままアップロードしたって大した容量にはならないわけだし、活用の仕方はかなりあるように思う。