

今日から准教授になりました。まあ肩書きなんてどうでもいいんですがお祝いはいつでもウェルカムです。
—
タイトルが一体どういうシチュエーションかと言われたら、まあたとえば顧客ごとに月間で購買した商品を比較したい場合とか。
サンプルデータの生成
import numpy as np; import random
L1 = ['A', 'B', 'C', 'D', 'E', 'F', 'G']
L2 = ['C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K']
N = 5
np.random.seed(2198); random.seed(0)
d = pd.DataFrame({
'n1': np.random.randint(low=0, high=len(L1)+1, size=N),
'n2': np.random.randint(low=0, high=len(L2)+1, size=N)
}, index=range(N))
d['l1'] = d['n1'].apply(lambda x: np.sort(random.sample(L1, x)))
d['l2'] = d['n2'].apply(lambda x: np.sort(random.sample(L2, x)))
display(d)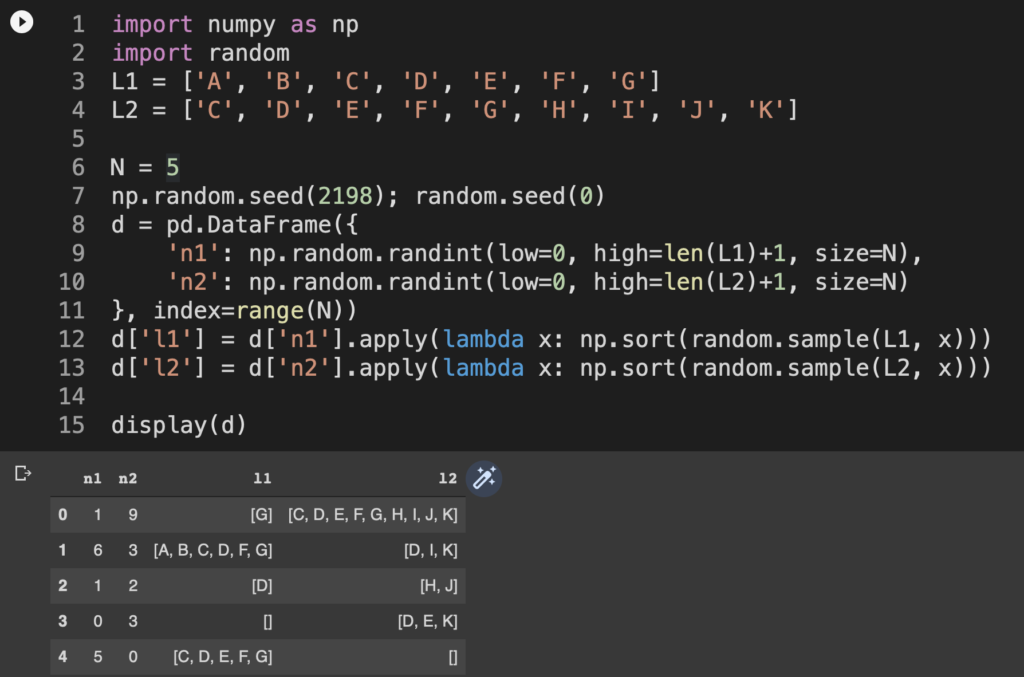
各インスタンス(オブザベーション)を顧客だと想定した場合に、l1が前月、l2が今月に購買された商品IDになってるようかイメージ。たとえばObs 2をみると、前月は商品Dのみを購入しているが今月はそれをやめてH, Jを購入している。
こういうデータが与えられている場合に、l1とl2というリスト2つのインアウトを調べたい。具体的には、いくつの項目がドロップアウトし、いくつの項目が新規採用されたのか。「そんなんダミー変数化すればええやん」という指摘ももっともなんだけど、上の例ではあくまで要素数がせいぜい9個だからいいものの、僕が実際に扱いたいデータではユニークな要素数が1万ぐらい、それがさらに12ヶ月×3年分ぐらいあるので、それを横方向にmulticolumn的に展開していくとダミー変数だけで36万個できることになる。だるすぎる。個数を調べるためだけにそんなことはやっていられない。
ということで思いつきでやっていく。
たとえばpandasにはある変数内の値がリストに含まれているかどうかを調べるisinがある(d[‘l1’].isin(l2)的なね)が、これの場合には変数の値(今回ならl1の、たとえば [A, B, C, D, F, G] 、というリスト全体をひとつの値として認識してしまうので、単なるisinではうまくいかない。
戦略としては、pandasのデータフレーム内の複数の要素を同時に呼び出す形で無名関数を呼べるのがベスト。とはいえ、d[‘l1’].apply(lambda x: x.isin(~))などとは書けない。この解決策は簡単で、データフレーム自体にapplyをかけ、axis=1を指定する。これによりデータフレーム内の各行ごとに要素ごとの計算を行ってくれる。
たとえば2つのリストl1, l2を2次元のリストとして結合することを考えれば、
d['l3'] = d.apply(lambda x: [x['l1'], x['l2']], axis = 1)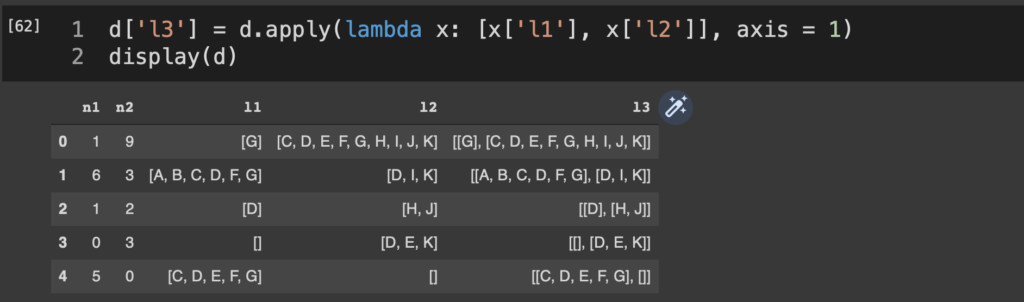
わざわざこんな書き方をしている以上当然だが、この処理は [ d[‘l1’], d[‘l2’] ] では走らない。その形で書くと、「d[‘l1’] というpd.Series全体」と「d[‘l2’] というpd.Series全体」とをひとつのリストに突っ込むことになる。今回はあくまで行単位で中のd[‘l1’].values[0] を見ていきたい。そのための処理となる。
(ちなみに一部の記事では文字型や数値型の変数の一部のオブザベーションだけにリストを挿入したりしているが、そういうのはバグの温床になるのでやめたほうがいい。型の中のスタイルは統一しておくべきで、そうしないとその変数を使った次の処理でもまたいちいち書き分けないといけなくなる。ちゃんとpandasは表計算ではなくデータベースだと考えた方がいい。)
すると、l1のリスト内の各要素がl2のリストに入っているかどうかを見ればいいので、たとえば
d['l2_isContinued'] = d.apply(lambda x: [ int(v in x['l1']) for v in x['l2']], axis = 1)
d['l2_NContinued'] = d['l2_isContinued'].apply(lambda x: np.sum(x))
display(d)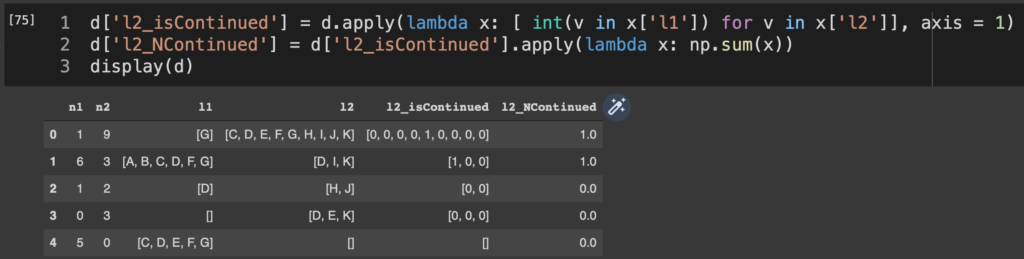
とすると、これはl2の中の要素がl1に入っていれば1, 入っていなければ0となるような0/1のリストl2_isContinuedと、l2_NContinuedを作成する処理になる。
リスト全体の要素数はn1, n2で取得できているので、新規採用数(NNew)や離脱数(NChurn)は、
d['l2_NChurn'] = d['n1'] - d['l2_NContinued']
d['l2_NNew'] = d['n2'] - d['l2_NContinued']
display(d)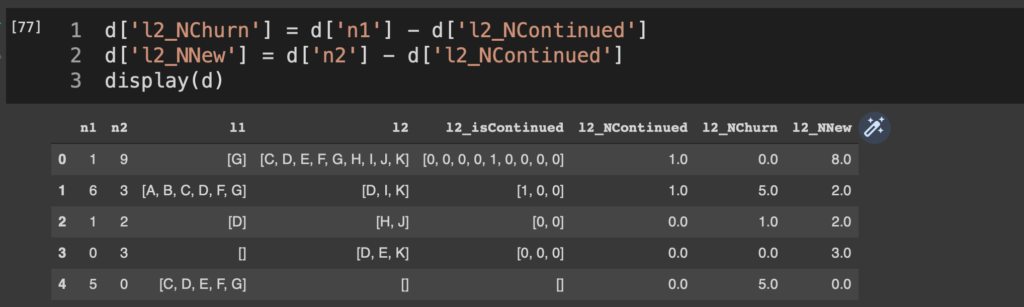
といった具合に算出できる。
んーーーPythonなんもわからん。