

直近の学会発表のためにYELPのデータセットを触ってみたいと思い立ったものの、今はちょうど出先にいて、合計10GB程度だとさすがにテザリングでダウンロードできるような容量ではない。かといってColabでCurlでも使ってダウンロードするにも、CSRFがかかっていて生のURL指定ではダウンロードできない。でも今は少し時間があるので触りたい。
最初はCSRFトークンを取得してうまくアクセスすることを考えていた。トークンの取得自体は簡単なんだけど、そこからトークン含めてPOSTしたりするのにSeleniumとrequestsを組み合わせるのが面倒でやめた。そしてせっかく昨日「Seleniumで動的スクレイピング」のコードを書いたわけだし、Colab + Seleniumでログインあるいはそれに近しいフォーム記入による認証を(正当に)かけた上で、Colab上でダウンロードしてそのままGoogle Driveにアップロードする形で実行することにした。
1. 準備
前稿と同様にColabとSeleniumで解決していくため、まずはwrapper (jpjacobpadilla/Google-Colab-Selenium)を入れつつ、Seleniumに関してその他の必要なものも個別にimportしていく。
!pip install google_colab_selenium
from google.colab import userdata
import google_colab_selenium as gs
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time

最初のchromedriverの立ち上げはこんな感じで。状況によって変わるのはオプション指定ぐらいかな。
url = 'https://www.yelp.com/dataset/download'
opt = Options()
for o in ['--headless','--disable-dev-shm-usage','--no-sandbox','--lang=ja','--window-size=1920,1080','--ignore-certificate-errors','--incognito']:
opt.add_argument(o)
driver = gs.Chrome(options=opt)
driver.get(url)
time.sleep(3)
特に重たい描画があるわけでもないのでsleepは3秒にしてある。
2. Colabで環境変数の登録
ipynbファイル上にパスワード等の情報を平文で入力することを避けるため、Colabに新たに環境変数の登録ができるようになった。今回のYELPデータセットのダウンロードページへの遷移では、CSRFとはいってもパスワードみたいな正式なCredentialsをsubmitするわけでもないんだけど、ただ、練習のためにColabに新しく実装された環境変数の登録を使ってみる。
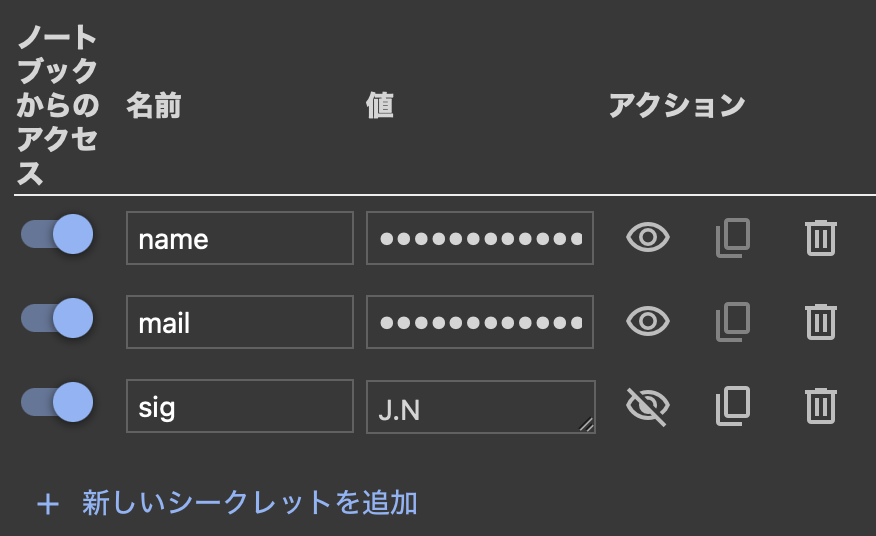
Colabの環境変数登録は左メニューバーの鍵マークから行う。今回必要なのは名前、メールアドレス、サイン代わりのイニシャルなので、それぞれname、mail、sigとして環境変数に登録する。

「新しいシークレットを追加」からkey-valueの組み合わせを登録することになる。
ColabのNotebookに登録された環境変数を読み出すには、userdata.get()を使う。たとえばnameを取得するなら、
from google.colab import userdata
userdata.get('name')

こんな感じ。少なくともコード上に平文でパスワードを入力することはなくなったので、今後API KEYとかもこうやって使っていくことになりそう。
3. 対象Webページの構造を知る
今回対象としているのはYelp Dataset (https://www.yelp.com/dataset/download)のページ。
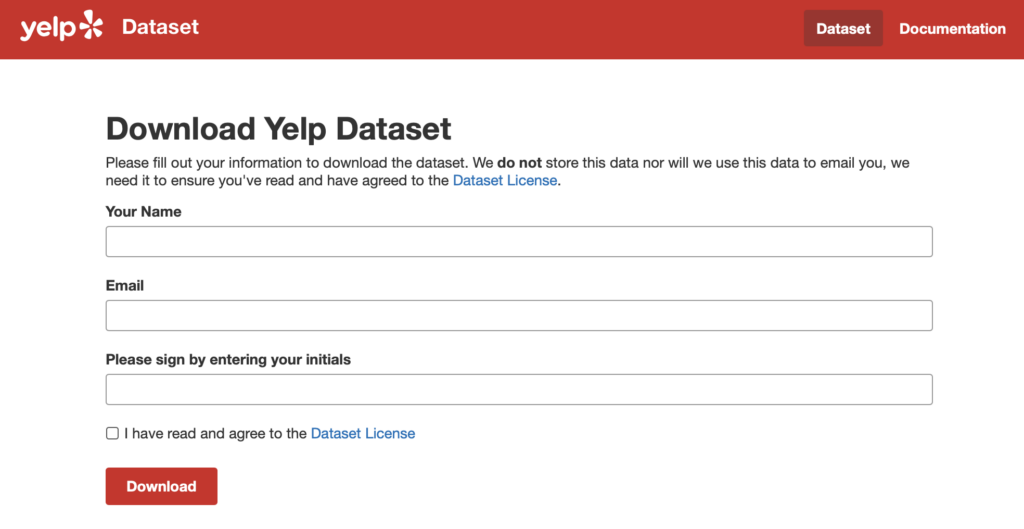
先の情報と、ちょっとしたTerms & Conditionsのチェックボックスがあるくらい。ここで名前、メールアドレス、イニシャル、チェックボックスのfillを行ってDownloadボタンを押すと、同じURLのまま
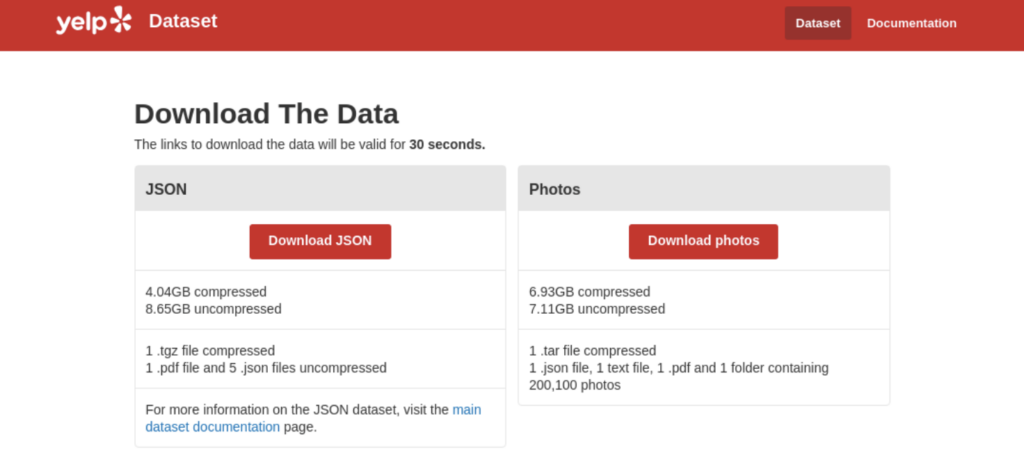
に移行する。これはReactで実装されてるっぽく、URL遷移がないのでBeautifulSoup4とか使うのはやっぱ面倒そうなんですよね。とはいえシンプルなのでSeleniumの練習くらいには実にちょうどいい。
フォームの実装自体は極めてシンプルなので、要素を調べると
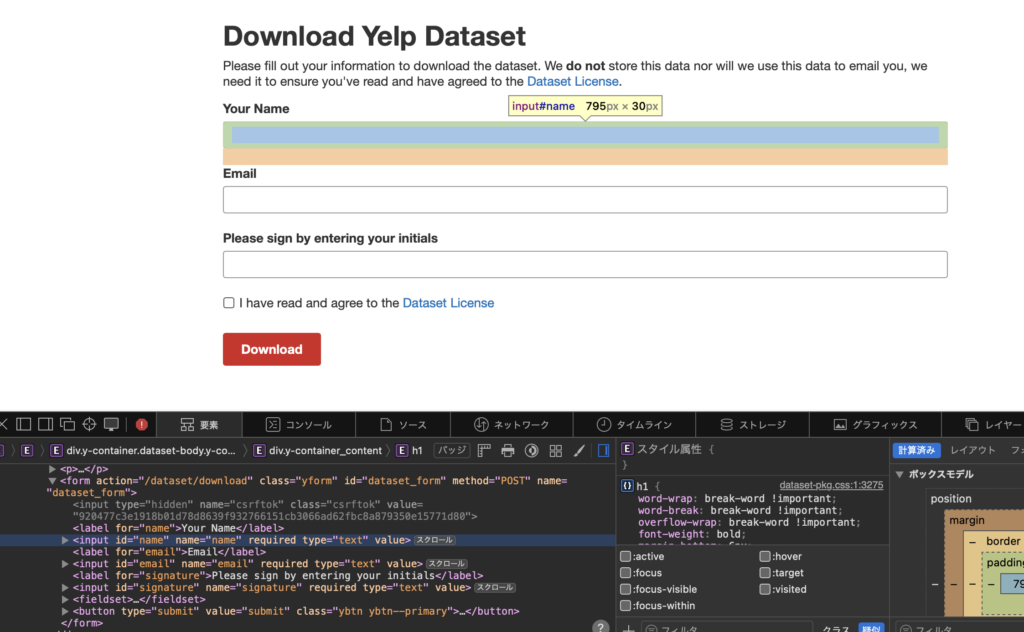
チェックボックス含め、inputタグ+id指定で全部取得できる。フォームも他にないので最初の要素を使えばいい。フォームに入力する場合はsend_keys()を、チェックボックスを埋めるならclick()でも使えばいい。
4. Seleniumで見てみる
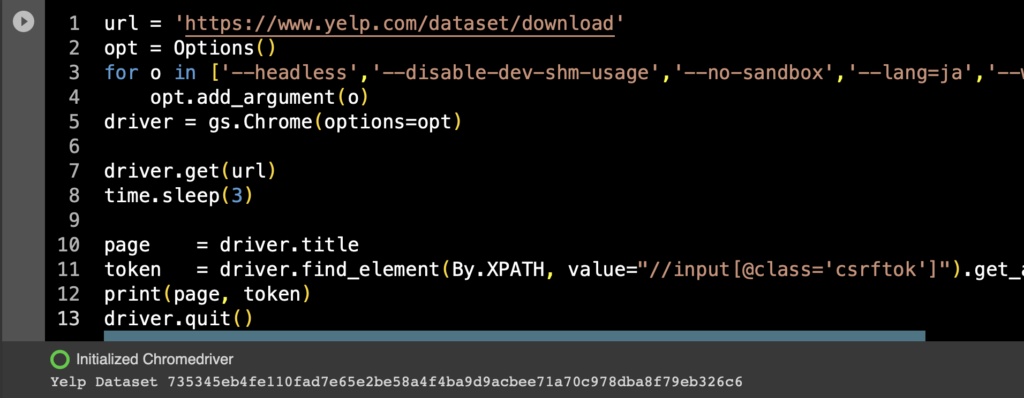
たとえばページタイトルとCSRFトークンだけ取得してみると、
page = driver.title
token = driver.find_element(By.XPATH, value="//input[@class='csrftok']").get_attribute('value')
print(page, token)
そして各要素の取得はこんな感じ。基本的に全部xpathでやればいい。
name = driver.find_element(By.XPATH, value="//input[@id='name']")
mail = driver.find_element(By.XPATH, value="//input[@id='email']")
sig = driver.find_element(By.XPATH, value="//input[@id='signature']")
term = driver.find_element(By.XPATH, value="//input[@id='terms_accepted']")

あとはそれぞれの値をfillしてあげればいいので、要素のsend_keys(‘value’)やclick()を使って、

name.send_keys(userdata.get('name'))
mail.send_keys(userdata.get('mail'))
sig.send_keys(userdata.get('sig'))
term.click()
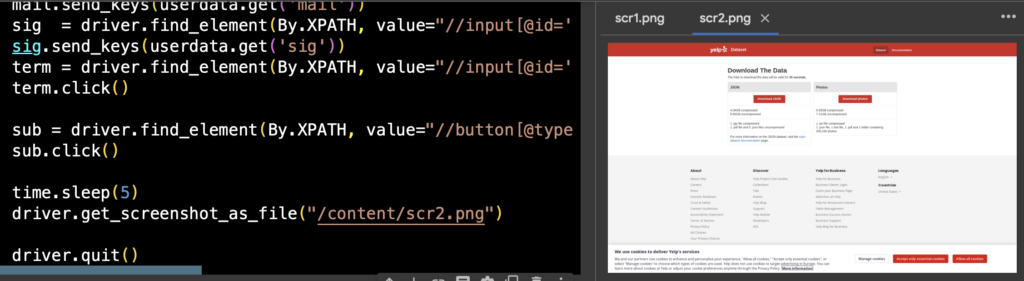
としてあげれば、フォームの作成は完了。あとは送信すると画面遷移が起きる。今回はsubmitせずに、あくまでGUIを操作してる感を出すためtype=submitのボタンを探して押してみる(=click)ことに。
sub = driver.find_element(By.XPATH, value="//button[@type='submit']")
sub.click()

実際get_screenshot_as_file()でスクショを画像で吐き出すとうまくいっていることがわかる。
5. ファイルのダウンロード
ここまできたらあとはダウンロードするだけ。ボタンは2つあって、それぞれ同じaタグにclass=”ybtn ybtn–primary”が付与されているので、find_elementsで全て取得して順番に中身を見てみる。
btns = driver.find_elements(By.XPATH, value="//a[@class='ybtn ybtn--primary']")
for btn in btns:
print(btn.get_attribute('href'))

2つのファイルyelp_dataset.tgzとyelp_photos.tgzのアクセストークン付きURLが手に入る。ここからクッキーを吸い出してあげたりすればColabからでもcurlなりrequests.getなりできるんだけど、今回はあくまでSeleniumでダウンロードまでやってみる。実際のダウンロードはこの<a>タグの要素をclickしてあげればいい。とりあえずダウンロードフォルダの指定をしておく。
dldir = '/content/drive/MyDrive/data/yelp/'
opt.add_experimental_option("prefs", {"download.default_directory": dldir })

ただしダウンロード中のchromedriverの継続など諸々ごちゃついたあれがある。そこはChromeのダウンロード用一時ファイルが存在するかどうかで判定する既存のルーチンを流用してダウンロード中かどうかを判定する関数を書いた。今回はタイムアウトなどは考慮しない。めんどくさいので。ただ、tgzのダウンロード中の一時ファイルがtar.crdownloadになっているのでちょっといじる。
def process_download(DIR, fname):
print('Begin Downloading...')
f = DIR+fname+'.tar.crdownload'
time.sleep(1)
print('Temp File:', f)
while os.path.isfile(f):
print(os.path.getsize(f))
time.sleep(1)
print('Done.')
time.sleep(5)

そして、aタグは2つあるのでループ使ってこんな感じかな。
# Download
btns = driver.find_elements(By.XPATH, value="//a[@class='ybtn ybtn--primary']")
for btn in btns:
btn.click()
process_download(DIR=dldir)

そしてそこから色々と修正して、最終的にこんな感じになった。