

*念のため付記しておくと、サーバーに負荷をかけるようなことや倫理的に望ましくないデータ取得はやめましょう。
JavaScriptなどでクライアント側での描画を行うWebサイト(SpotifyとかTikTokとか)は、BeautifulSoup4を使った静的なHTML取得ではスクレイピングができない。じゃあSeleniumでやればいいんじゃないのという話になるのだが、SeleniumはColabとの相性がいまいちよろしくない。ローカルで走るコードが走らなかったりする。
たとえばPATHに配置されているChromedriverは落としてきたバイナリとバージョンが違うだの、
WARNING:selenium.webdriver.common.selenium_manager:The chromedriver version (114.0.5735.90) detected in PATH at /usr/local/bin/chromedriver might not be compatible with the detected chrome version (119.0.6045.159); currently, chromedriver 119.0.6045.105 is recommended for chrome 119.*, so it is advised to delete the driver in PATH and retry
これに限らずかなりうるさく、5月に公開したコードがもう動かなくなっている。そこで誰かがwrapper (jpjacobpadilla/Google-Colab-Selenium)を作ってくれていた。ありがたい。
早速使ってみる。基本的にはpipでインストールでき、wrapperなのでパラメータなどはseleniumのものを流用できる。
!pip install google_colab_selenium
あとは今インストールしたパッケージとSeleniumを読み出してあげる。僕はその他自分が使うものも適当にインポートしています。
import google_colab_selenium as gs
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
import pandas as pd
import numpy as np

試しにひとつURLを指定し、今回はTikTokの情報を取得してみる。Optionsとかは割とざっくばらんに指定しています。
url = 'https://www.tiktok.com/music/アイドル-7216137897747941378'
options = Options()
options.add_argument("--headless")
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--no-sandbox")
options.add_argument("--lang=ja")
options.add_argument("--window-size=1920,1080")
options.add_argument("--disable-popup-blocking")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--incognito")
driver = gs.Chrome(options=options)
driver.get(url)
time.sleep(10)
page = driver.title
title = driver.find_element(By.XPATH, value="//h1[@data-e2e='music-title']").text
creator = driver.find_element(By.XPATH, value="//h2[@data-e2e='music-creator']").text
cnt = driver.find_element(By.XPATH, value="//h2[@data-e2e='music-video-count']").text
driver.quit()
print(page, title, creator, cnt)
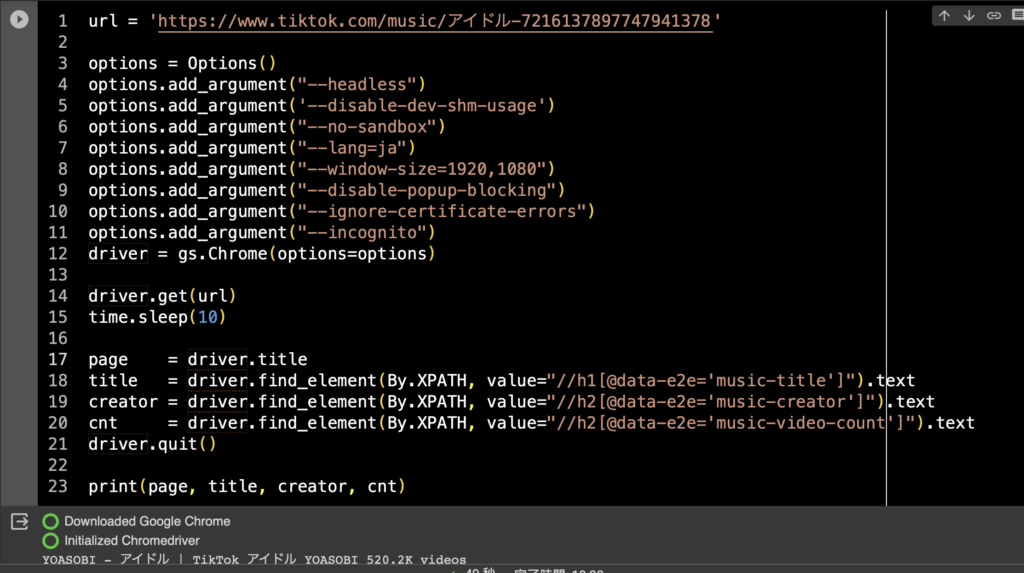
こんな感じ。走らせると、初回だけChromeのインストール、そして次からはInitializeが行われる。chromedriverはあくまで動的なので、quitするとインスタンスが終了してデータも取得できなくなる。よってquit前に必要な情報は取得しておく必要がある。
TikTokの音源ページでは、必要な情報は割とわかりやすくタグにまとまっている。
たとえば、h1, h2タグあたりで
- <h1 data-e2e=’music-title’>タグ:曲名
- <h2 data-e2e=’music-creator’>タグ:クリエーター名
- <h2 data-e2e=’music-video-count’>タグ:曲が使われている動画数
が取得できる。
これらを適当に関数にまとめてあげれば…
def count_one_video_used(driver, video_id = 'オリジナル楽曲-れるりり-7242640629258341122'):
print('処理開始:', video_id)
url = 'https://www.tiktok.com/music/' + video_id
driver.get(url)
time.sleep(np.random.randint(5,12)) # JavaScriptの描画を5-12秒ランダムに待つ
page=None; title=None; creator=None; cnt=None
page = driver.title
title = driver.find_element(By.XPATH, value="//h1[@data-e2e='music-title']").text
creator = driver.find_element(By.XPATH, value="//h2[@data-e2e='music-creator']").text
cnt = driver.find_element(By.XPATH, value="//h2[@data-e2e='music-video-count']").text
d = pd.DataFrame({
'video_id': [str(video_id)],
'page' : [str(page)],
'title': [str(title)],
'creator': [str(creator)],
'count': [str(cnt)]
})
print('結果:', str(video_id), str(page), str(title), str(creator), str(cnt))
return d
def count_all_video_used(ids):
options = Options()
options.add_argument("--headless")
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--no-sandbox")
options.add_argument("--lang=ja")
options.add_argument("--window-size=1920,1080") # Set the window size
#options.add_argument("--disable-infobars") # Disable the infobars
options.add_argument("--disable-popup-blocking") # Disable pop-ups
options.add_argument("--ignore-certificate-errors") # Ignore certificate errors
options.add_argument("--incognito") # Use Chrome in incognito mode
driver = gs.Chrome(options=options)
try:
for id in ids:
_d = count_one_video_used(driver=driver, video_id=id)
d = _d if id==ids[0] else pd.concat([d, _d], axis=0)
time.sleep(np.random.randint(1,4)) # 1-4秒ランダムに待機
finally:
driver.quit()
d['num'] = d['count'].apply(lambda x: x.split(' ')[0].replace('K','').replace('M','')).astype(float)
d['_count'] = 1
d.loc[ d['count'].str.find('K')>=0, '_count' ] = 1000
d.loc[ d['count'].str.find('M')>=0, '_count' ] = 1000000
d['count'] = d['num'] * d['_count']
return d.drop(columns=['num', '_count'])
そして実際の実行として、
ids = [
'オリジナル楽曲-れるりり-7242640629258341122',
'アイドル-ラスサビ-愛してる-ver-7223079274210084866',
'アイドル-7216137897747941378'
]
count_all_video_used(ids)
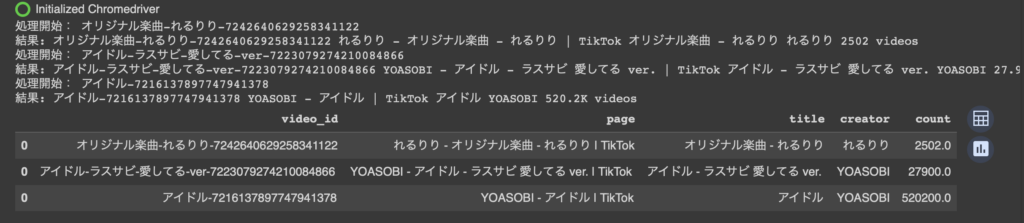
こんな感じでpandasのDataFrameとして取得できる。各動画の再生数やLike数なども似た方法で取得できる。