

事の発端
なんかループが遅い。久しぶりに大きなサイズのファイルを処理しなければいけなくなり、自作のミニバッチ処理みたいなのを組んでみた。バッチ処理と機械学習のミニバッチ学習から造語を作ってしまっている。
とりあえずのところPythonで処理中のプログレスバーを表示させるtqdmで処理を眺めてみると、どうも1 iterationあたりの所要時間がループの進行とともにどんどん遅くなっていく挙動が確認できる。これはローカルのMacBook Pro(M2 Max, メモリ96GB)のAdacondaでも、Google Colabのハイメモリでも同じような動きをしている。
やっている作業としては、pandasのDataFrameを作り、そこに1987897行のテキストデータ(まあユーザーデータとでも考えてくれればよい)を1行ずつ処理して追加していく作業。これを当初は全データ一気に進めていたんだけど、ローカルでも途中から話にならないぐらいの遅さになってしまったので中断し、細切れにして処理していくことにした。変わるのは基本的にDataFrameをpd.concat()で結合していく処理の部分だけなので、そこがボトルネックになってどんどん重くなっていっていることが容易に想像できる。
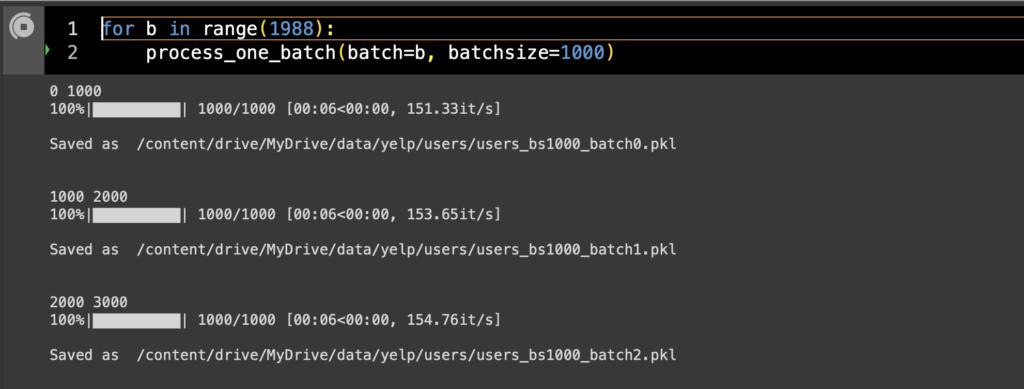
1987897データをバッチサイズ100, 1000, 10000それぞれで分割してバッチごとの処理時間を測ってみたところバッチサイズ1万があきらかに遅い。
| バッチサイズ | 10000 | 1000 | 100 |
| バッチ数 | 199 | 1988 | 19879 |
| sec/batch | 205 | 6 | <1 |
| sec/obs | 0.0205 | 0.006 | <0.01 |
| total (hour) | 11.3 | 3.3 | <5.5 |
tqdmのせいではない
tqdmは一般的に処理が遅くなるといわれるので、一応tqdmがあるパターンとないパターンでも比較をしてみた。
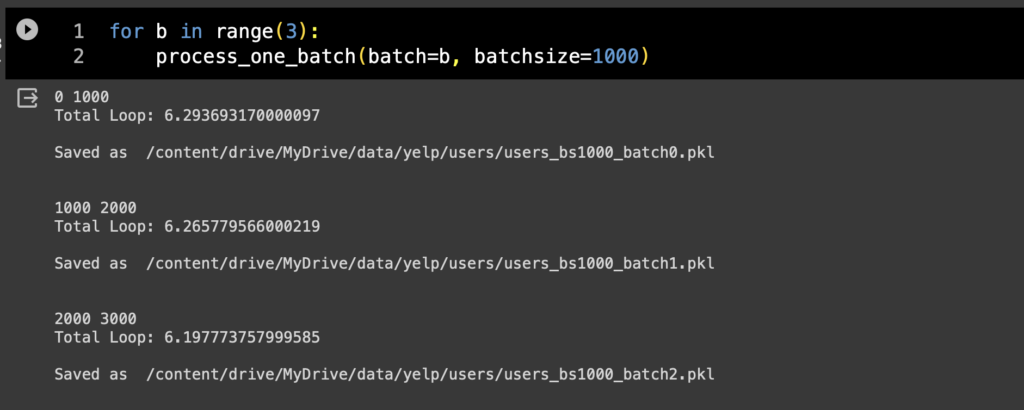
tqdmの表示ではミリ秒以下が切り捨てられているものの、使わないバージョンと比べてもその差は誤差程度でしかない。
やっぱpandasのせい
まあtqdm以上にそもそもpandasが遅いといわれるわけなので、こっちも使わないバージョンをやってみる。
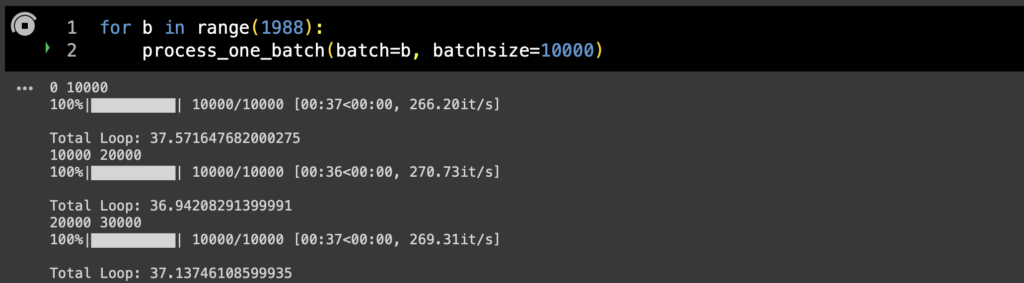
ループ内でpd.concatの処理をはずしたところ、バッチサイズ10000でも1バッチあたり37秒とあきらかに早くなった(さっきは205秒)。もちろんループ内の処理が1つ減るわけなので純粋な比較はできないわけだけれど、少なくともバッチ内の処理の中でイテレーションごとにどんどん処理ペースが落ちていく挙動がなくなったことから、やはりこれのせいっぽい。
…とはいっても、テキストファイルを1行ずつパースしてDataFrameにしていく作業は不可避なので、pd.concatの回数を減らすことが重要になる。っていうことは1000 Obsのミニバッチ1988個をさらに結合させるぐらいがベストの速度かもしれない。
まあこれが嫌ならSQL使えって話ですわな。