

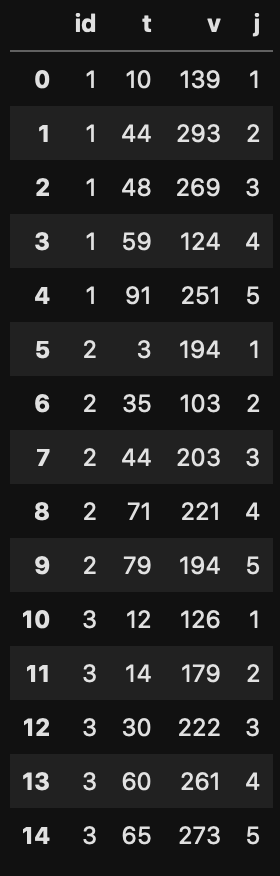
pandasの挙動を調べることがデータサイエンスだとは思わないけど、気になることができたので残しておく。主には join の挙動として、(1) pandasの index に重複があってもちゃんとマージしてくれるのか、 (2) groupby変数と異なる変数をindexにしていた時のjoinの挙動の2点を念のため検証しておく。今までこれが不安でずいぶん遠回りをしていたので。
サンプルとして消費者 i が j 回目の購買として時間 t に金額 v を支払うことを考える。ここで
$$ i \in N, ~~ t \in T, ~~ j \in J $$
として、極めて適当にpandasでデータセットを作る。本当は各種挙動に対して適した確率分布を選ぶべきではあるものの、今回はそれが目的なわけではないのでuniformと並び替えで済ます。
import numpy as np
import pandas as pd
N = 3; T = 100; J = 5;
np.random.seed(1)
d = pd.DataFrame({
'id': np.sort([i+1001 for i in range(N)]*J),
't' : np.int64(np.random.uniform(low=1,high=T,size=N*J)),
'v' : np.int64(np.random.uniform(low=100,high=300,size=N*J))
})
d = d.sort_values(['id', 't']).drop_duplicates(['id', 't']).set_index('id')#.reset_index(drop=True)
d['j'] = d.groupby('id').cumcount() + 1j は i ごとのグループ内連番として cumcount() で。なんだかんだこれが一番簡単。
単位時間 t を日にちとして(つまり t = 1 が1日目)、消費者ごとに最初の利用日から30日間の行動をRFMの3指標で集計する。月間の集計ではないところがひとつ面倒なポイント。
まずは各消費者ごとに異なる初期利用から30日間のデータだけを抽出する。消費者ごとの初回利用日 first を本体 d にくっつけて t と比較する。
d['first'] = d.groupby('id')['t'].first()このとき元のデータセットの index がちゃんと id に設定されていれば、
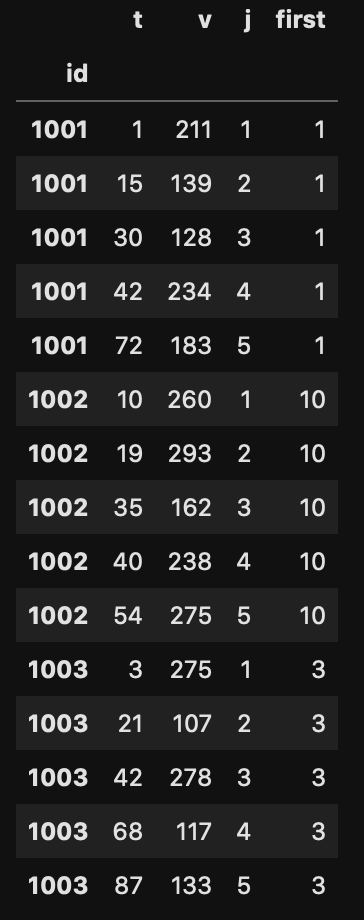
で正しく変数を追加することができる。その際には index に重複があっても同じindexにはちゃんと同じ値を差し込んでくれる。これは今の処理で first 変数を作成するときに、groupby(‘id’) すると idをindex としたpd.Series が生成されるから。その証拠に、
f = d.groupby('id').first()[['t']].rename(columns = {'t': 'first'})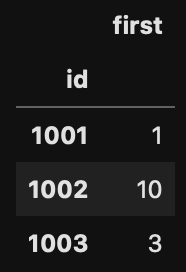
で同じものを単体のdfにすると、id が index に指定されていることがわかる。これを d.join(f) すれば先ほどと同じ挙動で元のDataFrameに結合できる。
しかし、元のデータセット d の index が id になっていない状態で同じようにSeriesを追加すると、
d = d.reset_index(drop = False)
d['first'] = d.join(f)
reset_index 
join
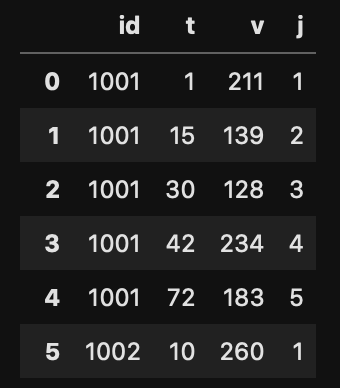
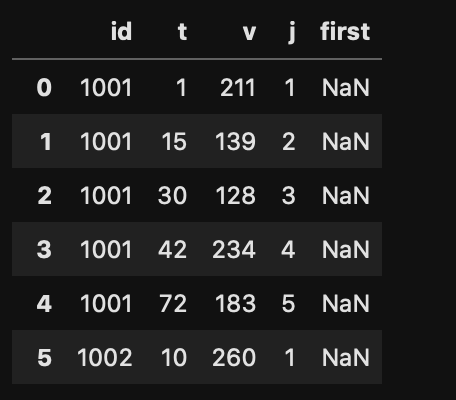
groupby変数としての id と同じ値の index のところに first の値が嵌め込まれることになる。当然挙動としては本来の意図とは異なるものになる。
ここでポイントになることとして、groupby を用いた集計では mean や sum など元のデータセットとはオブザベーション数が変わってしまうような集計方法については上のとおり元のデータセットとindexが一致している必要がある。
しかし、一番上でサンプルデータを作成した時から既にそうなのだが、 仮に大元のDataFrame上で既に reset_index していたとしても、 cumcount のように元データとオブザベーション数が一致するような処理は groupby 変数とindex変数が一致していなくても正しい挙動をする。
現にreset_index() してからcumcountの集計を行った場合のSeriesを確認しても、
d.reset_index(drop=True).groupby('id').cumcount()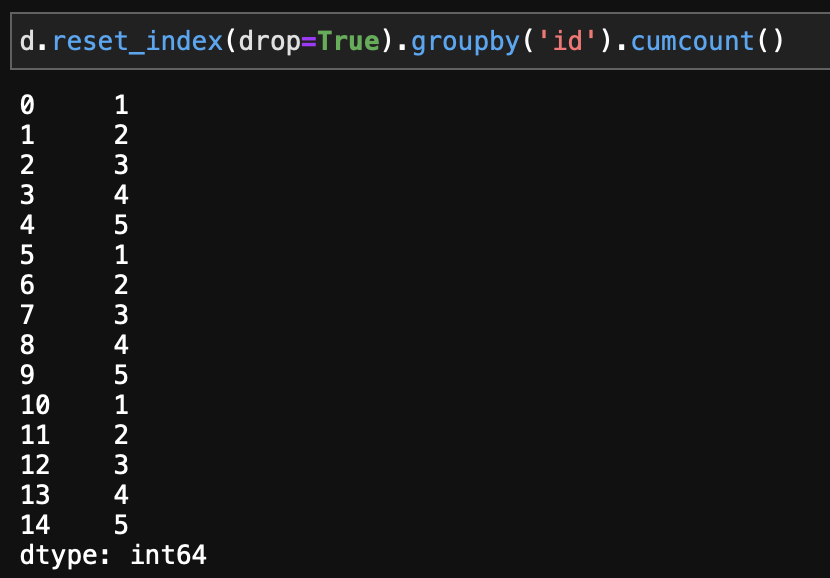
idでグループ化していても出てきた Series は リセット後の index で集計されている。だからそのままでも正しく join される。
ここまでできれば、あとは初回利用から30日間でDataFrameを条件抽出すれば済むので、
d30 = d[ d['t'] < d['first'] + 29 ]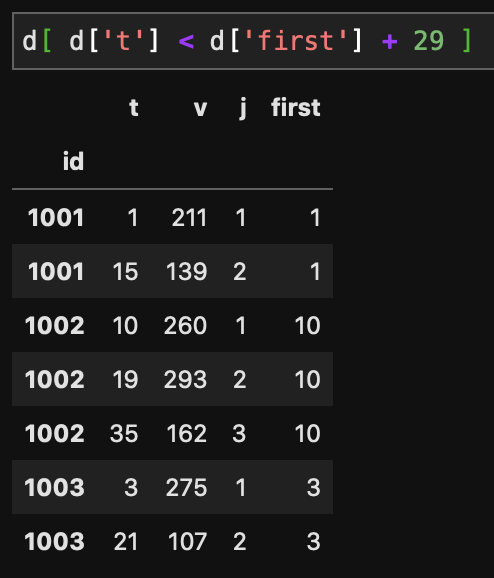
あとは普通に集計すればいい。RFMだけサクッと集計。
rfm = d30.groupby('id').last()
rfm['R'] = rfm['first'] + 29 - rfm['t']
rfm['F'] = d30.groupby('id')['t'].nunique()
rfm['M'] = d30.groupby('id')['v'].sum()
display(rfm[['R', 'F', 'M']])
とりあえず気になっていたことは確認できたので終わり。
ちなみに思いつきで後から追記したりやり直したりした関係でseedの値が変わって集計が変になってるかもしれん。