

Stable Diffusion 2.1やっばいすね。1.x系と精度が全然違う。
ちょっとしたMVでも作ってみるかと思ってベース画像を作った。これはStable Diffusion 2.1のAUTOMATIC1111で作ったものをさらにImprintで修正した。

現状この辺のテクノロジーで動画を作ろうとすると、基本的にはstable-diffusion-videosを使ってプロンプト+image-to-imageで2時点の画像から画像へと連続的に変化させていくか、deforum-stable-diffusionみたいに与えられた画像のレイアウトを変えてそこを補完させる形で連続的に変化させていくかのどちらかが多い。
stable-diffusion-videos(これ以降sdvと表記)の便利さはなかなかにすごいものがあって、StableDiffusionWalkPipeline.from_pretrained()でモデルIDを指定することでStable Diffusion 1.x系だけではなくWaifu diffusionなんかも使える。プロンプトとseedの指定をうまく組み合わせると、ちゃんと動画間でシーンがつながっている連続した出力を生成できるので、あるシーンから異なる2つの展開を作ったりも簡単にできる。試したければ、nateraw/stable-diffusion-videosに説明がある。あるいはopen-in-colabのリンクを直貼りしておきます。
ただ、2023年1月6日時点まで、stable-diffusion-videosでStable Diffusion 2.1(Hugging Face: stabilityai/stable-diffusion-2-1)を使おうとすると、
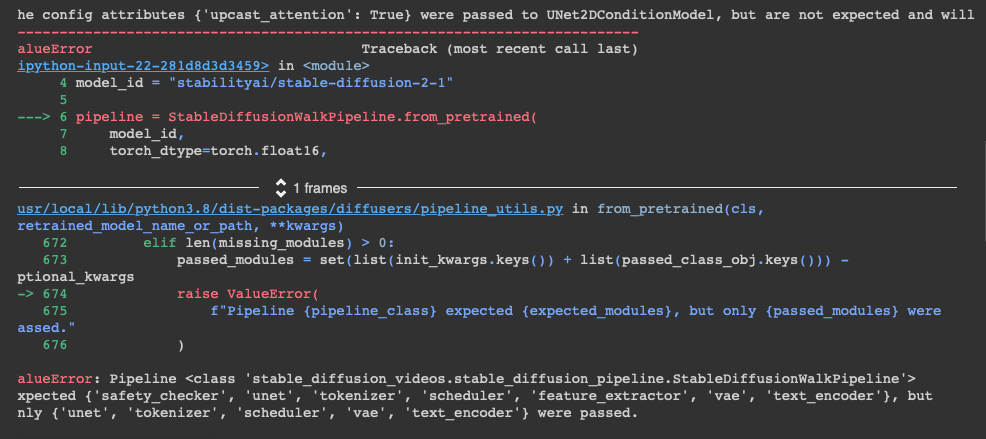
ValueError: Pipeline <class ‘stable_diffusion_videos.stable_diffusion_pipeline.StableDiffusionWalkPipeline’> expected {‘safety_checker’, ‘unet’, ‘tokenizer’, ‘scheduler’, ‘feature_extractor’, ‘vae’, ‘text_encoder’}, but only {‘unet’, ‘tokenizer’, ‘scheduler’, ‘vae’, ‘text_encoder’} were passed.
というエラーが出ていた。要は引数が足りないと怒られる。
これはsdvのIssues Stable diffusion 2-1 #129で報告されておりずっと注視していた。
そしてしばらくしてsdv開発者のnaterawが気付いて一晩で直った。
現状ではPyTorchのautocastの挙動で引っかかるので、
!pip install git+https://github.com/nateraw/stable-diffusion-videos@remove-autocast
で修正版のバージョンをインストールしてから
import torch
from stable_diffusion_videos import StableDiffusionWalkPipeline
from diffusers import DPMSolverMultistepScheduler
model_id = "stabilityai/stable-diffusion-2-1"
pipeline = StableDiffusionWalkPipeline.from_pretrained(
model_id,
feature_extractor=None,
safety_checker=None,
revision="fp16",
torch_dtype=torch.float16,
).to("cuda")
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
interface = Interface(pipeline)
Issue上ではpipeになってるんだけど、sdvの既存のコードとの整合性を取るためpipelineに書き換えています。
これで動く。
2023/02/25追記:
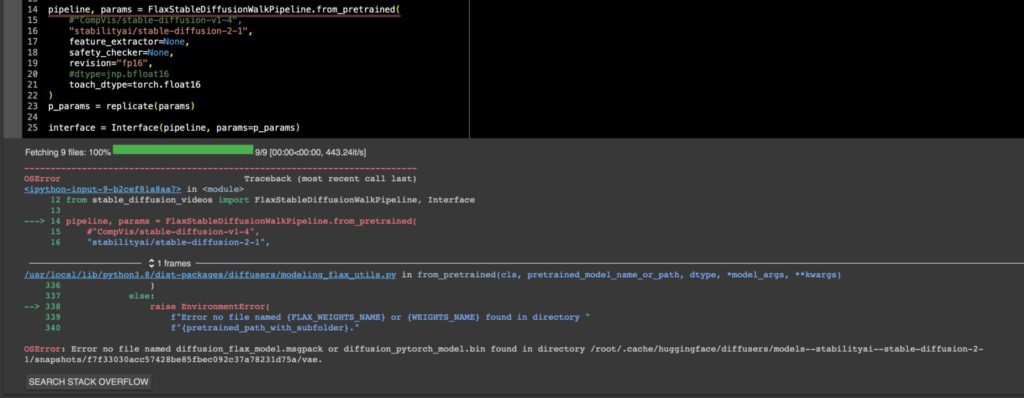
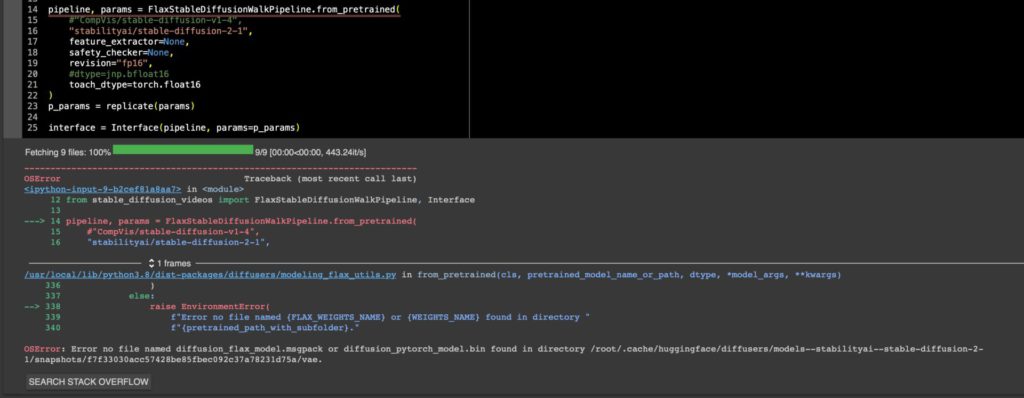
ちなみに新しく書かれたColabのTPU向けflax_stable_diffusion_videosでは今のところSD2.1は動かないんじゃないかな。これはSD1.4を走らせているFlax版ではjax.numpy=jnpのjnp.bf16によるrevision=”bf16″を使ってるんだけど、上のコードでも分かるとおりGPU版はdtype=torch.float16のfp16 revisionを使っていて、GPU版のfp16モデルはFlaxの方にはまだ追加されてない。だからリストに入ってなくてエラーが返ってくるだけ。
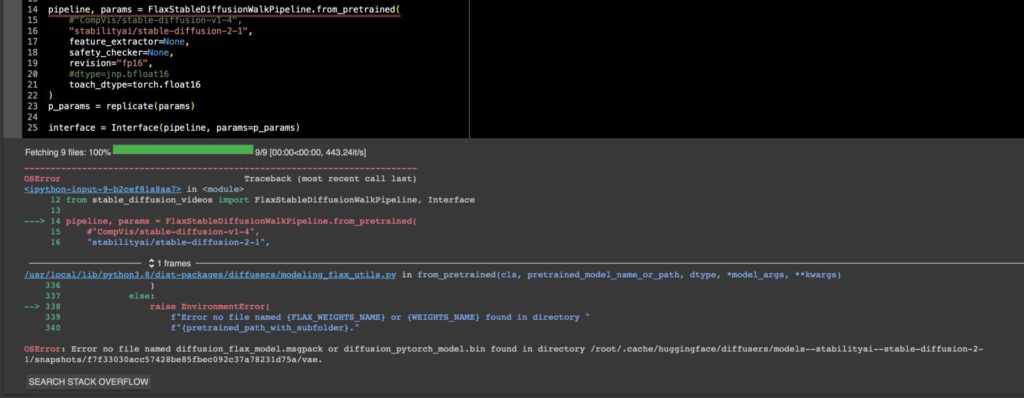
OSError: Error no file named diffusion_flax_model.msgpack or diffusion_pytorch_model.bin found in directory /root/.cache/huggingface/diffusers/models–stabilityai–stable-diffusion-2-1/snapshots/f7f33030acc57428be85fbec092c37a78231d75a/vae.
だからといって、bf16で無理やり走らせようとすると、当然対応してないっつってウェイトが大量に初期化される。
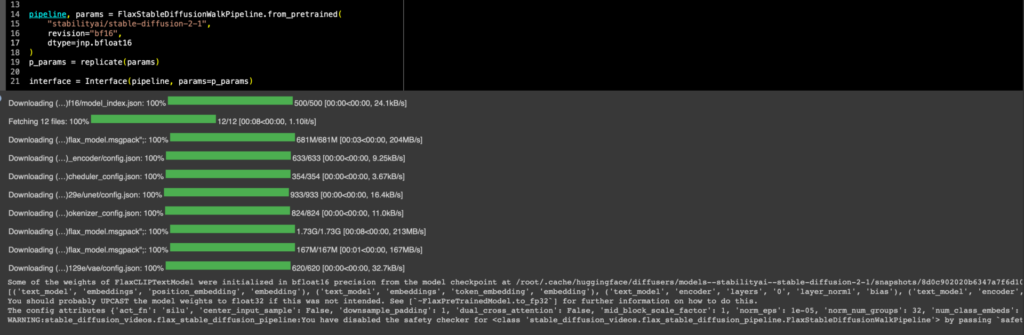
だから、おそらくprecisionを普通のnumpyとかtorchの値からjax.numpyに(つまりTorch tensorからjax arrayに)変換してあげればそれで動くんだろうと思う(それこそ画像の中でも気に入らないなら自分でUPSCALEしろって書いてある)し、頑張れば自力でなんとかできそうな気もするんだけど。まあきっと誰かがやるだろう。