

あの日人類は思い出した……メモリに配慮したコーディングがこんなに面倒なのだということを……
(研究費の関係でColabの請求日を毎月1日に変更したくてやむをえずPro+を一時的に解約したのだけれど、めちゃくちゃ不便です。2月以降は研究費を残しておくこと自体ちょっと嫌な顔されるし、お願いだから早く年払いできるようになってくれ。)
—
これは前々からわかっていたことではあるものの、自分への戒めとして書き残しておく。
僕は普段分析にあたりそれぞれの機能を関数化して使っていて、たとえば以下のような生データ
import pandas as pd
from numpy.random import randint
n = 20
raw = pd.DataFrame({
'id': randint(low=1, high=4, size=n),
'x1': range(n),
'x2': randint(low=0, high=3, size=n)
})

が与えられていたとして、それを触るのにこうやって(実際はもうちょっとまともなことやってるけどそれは今どうでもいい)、関数内でやりたいことやって結果だけを返して分析用のデータにくっつけていく。
def mean_x1_by_user(d):
g = d.groupby('id').mean()[['x1']]
return g.rename(columns={'x1':'meanx1'})
g = mean_x1_by_user(d = raw)
def most_used_x2_by_user(d):
g = d.groupby(['id'])['x2'].value_counts().to_frame()
g = g.rename(columns={'x2':'mostx2'}).reset_index(drop=False)
return g.groupby('id').first()[['mostx2']]
_ = most_used_x2_by_user(d = raw)
g = g.join(_)
これは第一には、毎回何も触っていない状態の生データを与えるところから処理を始めたいという思いがあるからです。そして、僕は変数名として(dとかgとか)同じ名前ばかり使う傾向にあるので、タスクごとに名前空間を切り分けたくてこういうことをやっているわけですね。
んで、このやり方をしていて時々陥りがちなのが、名前空間を切り分けて関数内でいじった結果は、returnしない限りグローバル空間には出てこないはずだという思い込みです。たとえば、
def add1(x1):
x1 += 1
print('関数内', x1)
x1 = 1
print('定義直後', x1)
add1(x1 = x1)
print('処理後', x1)

これなんかも、関数add1の中でオブジェクトx1に1を足しているけど、returnしてないから関数走らせた後のグローバル空間でもう一度x1を表示させてもその値に変化はないわけです(という書き方をするのは後述の通り実は語弊があるわけですが)。
それが、returnしてx1を上書きしてあげて初めて、
def add1(x1):
x1 += 1
print('関数内', x1)
return x1
x1 = 1
print('定義直後', x1)
x1 = add1(x1 = x1)
print('処理後', x1)

処理後のx1の値が変化する。
そう思ってしまうんですよ。
でもこれが案外そうでもなくて、先のpandasのデータを使うとすれば、
import pandas as pd
n = 5
d = pd.DataFrame({
'x1':range(n),
'x2':range(n)
})
def process1(d):
d['x2'] = 1
print('関数内-----')
display(d.head(3))
print('\n定義直後-----')
display(d.head(3))
process1(d = d)
print('\n処理後-----')
display(d.head(3))
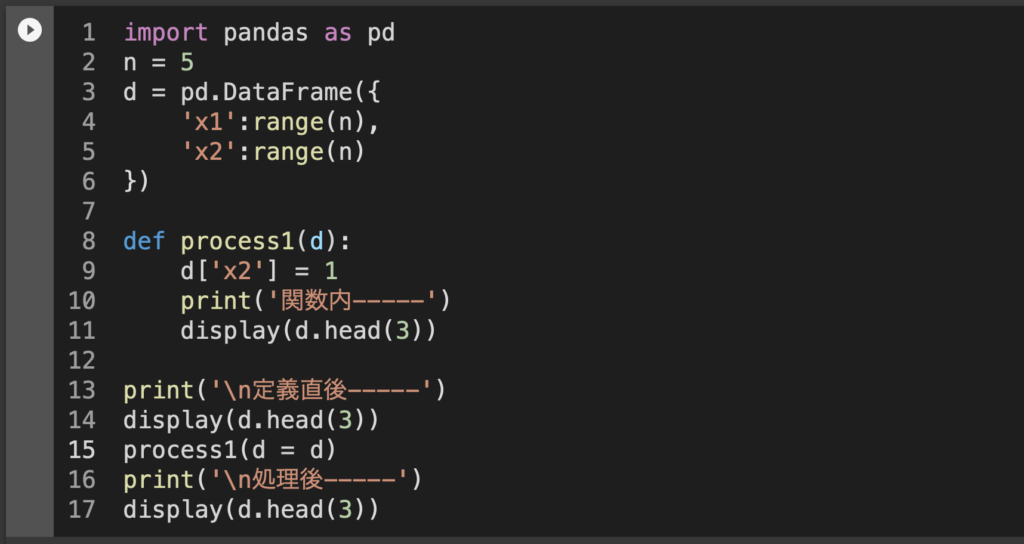
これ、関数process1に突っ込んだデータフレームdは関数内部でx2の値を上書きしてるわけですね。とはいえ別にreturnしてるわけではないんだけど、結果は…
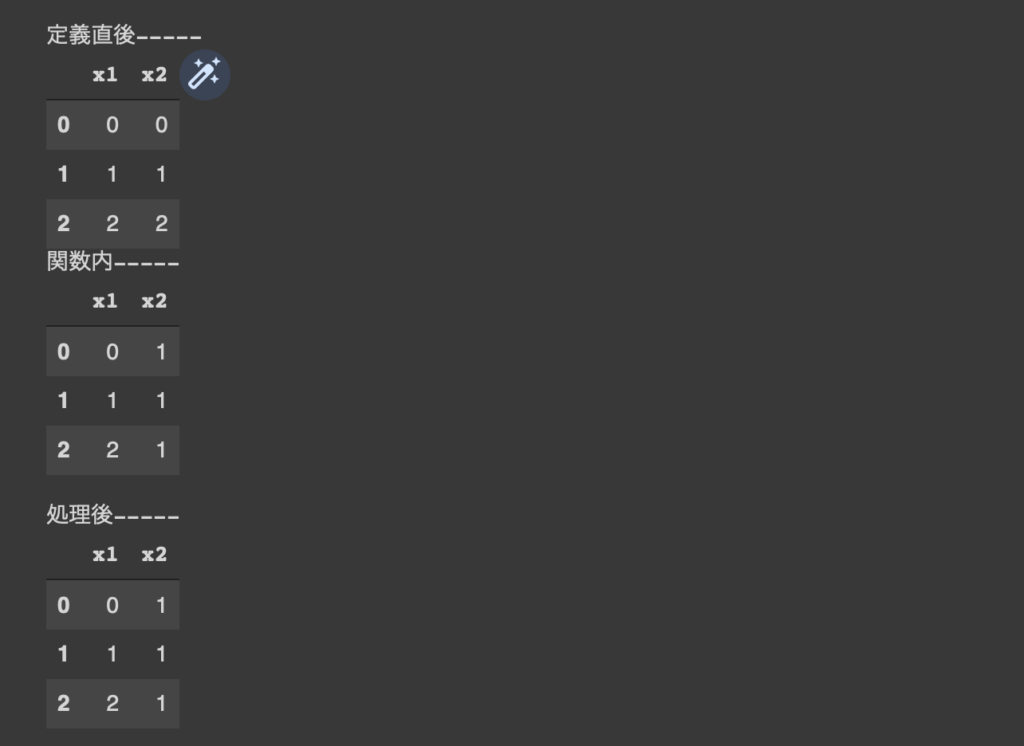
値が変わるんですよね。これはPythonで全てのオブジェクトに振られているオブジェクトIDが、引数として関数内に渡された時にもグローバル空間から変わっていないからです。
print('\n定義直後-----')
print('ID:',id(d))
display(d.head(3))
process1(d = d)
print('\n処理後-----')
print('ID:',id(d))
display(d.head(3))
こんな感じで中身の確認と一緒にオブジェクトIDも吐くようにすると、
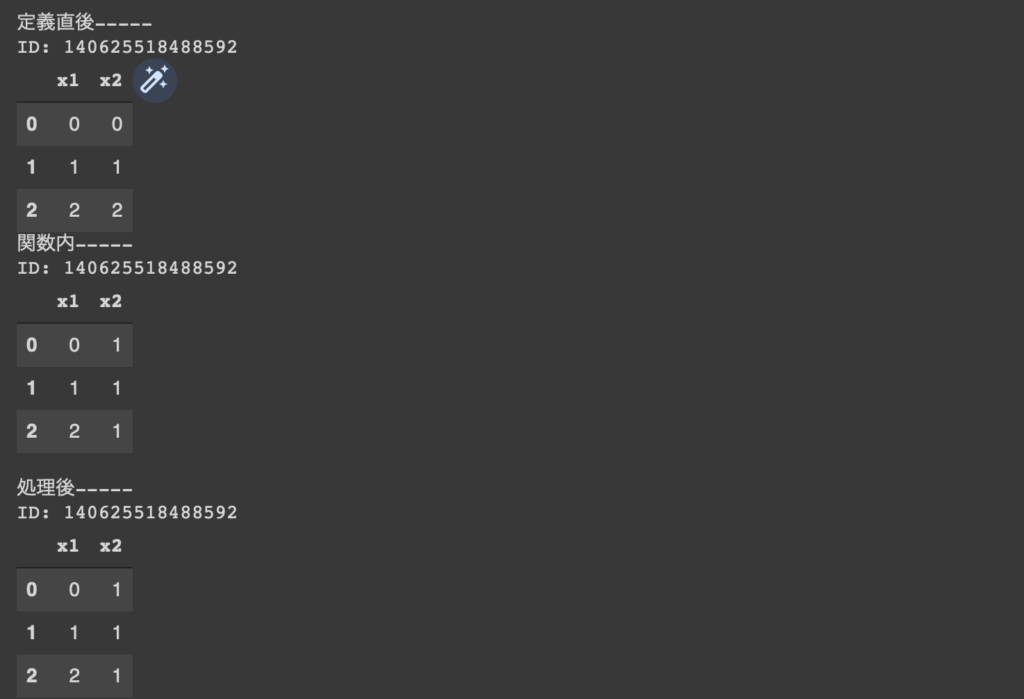
確かにオブジェクトIDはすべて同じであることがわかる。つまり、関数の中でオブジェクトをいじった場合に、それが同一のオブジェクトIDになっているとグローバル空間のオブジェクトまで上書きされる。
こういう現象が発生するかどうかにはまあ色々あるんだけど、その辺りは僕が解説することでもないので割愛するとしても、こういう時にはdeepcopyでも使えばいい。deepcopyではオブジェクトを別のオブジェクトIDで複製する。たとえば関数process1の頭でdeepcopyするように書き換えると、
from copy import deepcopy
def process1(d):
d = deepcopy(d)
d['x2'] = 1
print('関数内-----')
print('ID:',id(d))
display(d.head(3))
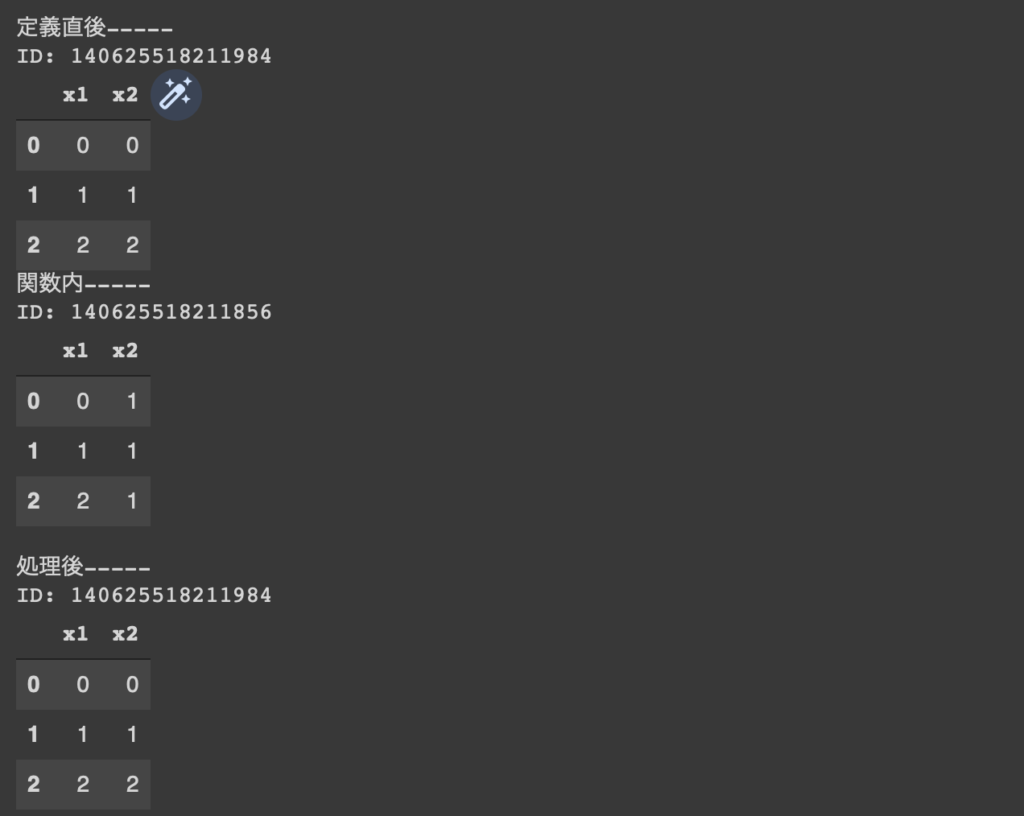
関数内で参照しているものだけオブジェクトIDが変化したことがわかる。そこで値をいじったとしても、変数名は同じでも実際には異なるオブジェクトを参照しているので、処理後のグローバル上のオブジェクトで値が上書きされることはない。
とはいえ、ビッグデータを扱う人間がdeepcopyを多用しはじめるとメモリがいくらあっても足りない(なによりなんかダサい)ので、個人的には滅多に使わないように心がけてるけど。今日1年ぶりぐらいに諸事情で使わざるを得なくなった。
そんな感じ。Python何もわからん。