

久々にPythonで音作りをして遊ぶことにした。Colabだけでもそれなりに遊べるので1から全部やってみることにする。ずいぶん前に信号処理で遊んでた件以降、正直たまに細々とやっていた程度であまり触っていなかった。
もちろんprettymidiとか色々遊べるライブラリはあるんだけど、その辺使うぐらいならMax for Liveでやればいいので音声信号レベルで作っていく。ということで、音声データの管理は本業でもやっているpandas DataFrameをベースにしていくことにする。
準備:クラスを作って最低限鳴らしてみる

import numpy as np
import pandas as pd
from IPython.display import Audio
あまりやらないんだけど勉強も兼ねて自分でクラスを定義していく。私はpandasをいじくり返してデータを分析する人で自分でクラスを作ったりすることは本当にないので、だいぶしょうもないコードになると思うけど今回そこは許してほしい。
今回はAudioDataFrameというクラスを作ってみる。AudioDataFrameというのはpandasでジオコーディングするGeoDataFrame(GeoPandasパッケージ)のネーミングを参考にしているのだけれど、とはいえdfは継承するのが面倒なので適当に使っていく。
まずは基本的な情報としてサンプリング周波数sampling_freq、BPM、小節数barsを入れて、後々必要になりそうな情報を生成させておく。

class AudioDataFrame:
def __init__(self, bpm = 120, bars = 1, sampling_freq=44100):
self.bpm = bpm
self.bars = bars
self.beats = 4 * bars
self.seconds = 60 / bpm * self.beats
self.secfreqperbeat = self.seconds * sampling_freq / self.beats
self.sampling_freq = sampling_freq
self.audio = self.generate_blank_signal()
- beat:今回は4/4と考えて小節数から合計の拍数
- seconds:生成する音声ファイルの長さをサンプリング周波数、BPM、小節数からから計算
- secfreqperbeat:1拍あたりの秒数(周波数ベース)
- audio:下で作っていく
self.audioを最終的な音声データを管理するDataFrameにしていきたい。とりあえず初期化した時点で、秒数分だけの無音の音声ファイルを作成してみる。

def generate_blank_signal(self):
t = np.arange(self.sampling_freq * self.seconds)
y = t * 0
d = pd.DataFrame({
't':t, 'y':y
})
return d
横軸をt(for time)、縦軸をyとして、サンプリング周波数は1秒あたりのサンプリング回数なので、そこに秒数をかけてやれば総サンプリング回数が算出できる。
ついでに波形の図示のための関数show()を作る。図示では、作成した波形がクリップしたり片寄ったりその他諸々が起きても表示が変わらないよう、横軸t、縦軸y、値域を-1~1まででハードコーディングした。

def show(self):
self.audio.plot(x='t', y='y', ylim=[-1,1])
とりあえず無音の波形を作ったところまで図示してみる。まずAudioDataFrame()でインスタンスを立ち上げる。この時点で初期化された無音状態の波形が作成されるので、show()で早速見てみる。
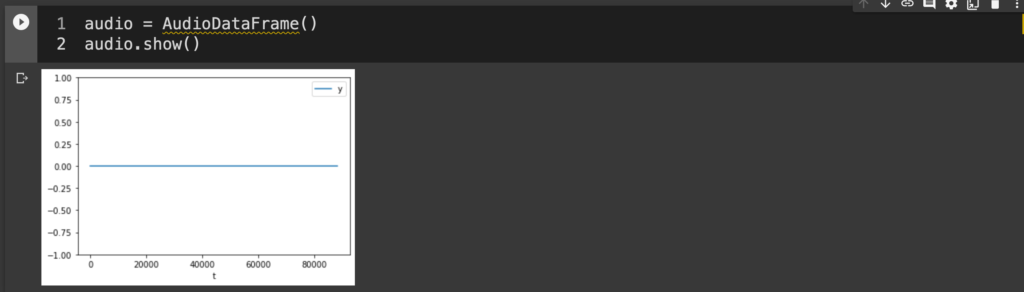
audio = AudioDataFrame()
audio.show()
まだ波形が空なのでこれだけ見ても面白くないけど。
ついでに再生用の関数play()も先に実装しておく。ただし、のちのち色々といじるのに面倒なことが起きると嫌なので、音がクリップしないよう今回はとりあえず絶対値1よりも大きな信号については1, -1を超えないよう機械的にリミッティングしてあげる。
def play(self, isLimit=True):
if isLimit:
self.audio.loc[ self.audio['y'] > 1, 'y' ] = 1
self.audio.loc[ self.audio['y'] < -1, 'y' ] = -1
display(Audio(self.audio['y'], rate=self.sampling_freq))
再生時は、最初にimportしたIPython.displayの中のAudioを使う。こいつに波形の値(今回でいえばaudio[‘y’]の値だけ)と、サンプリング周波数の値を与えてあげる。これでIPythonが自動的に音声ファイルを作成してくれる。大変ありがたい。後はそれごとdisplayしてあげれば…
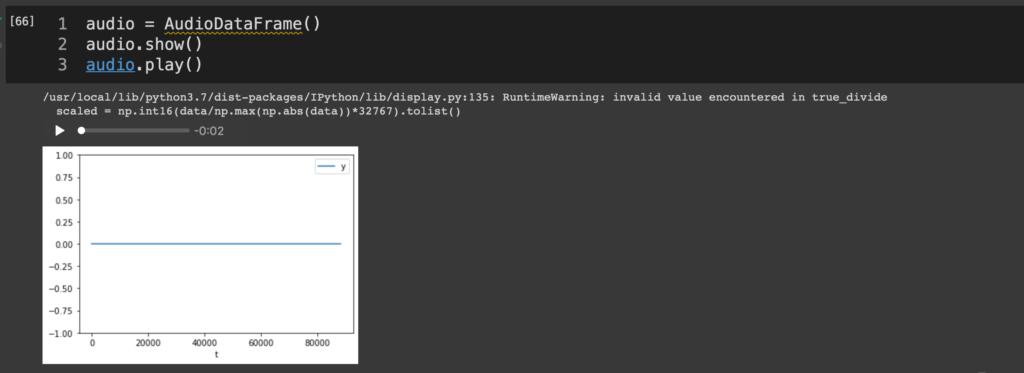
audio = AudioDataFrame()
audio.show()
audio.play()
Colabのアウトプット領域のなかに見慣れない再生ボタンが現れる。今回でいえば「▶︎ —- -0:02」みたいなのが出てきている。これを押すと、無音だが音声ファイルが再生される。
とはいえ全く音が鳴らない状態の再生では相変わらず面白味がない。とにかく一旦音を鳴らしたいということであれば、先ほどブランクの音声を作成した時点の関数を書き換えて、y=t*0を適当に(本当に適当に)np.sin(t)とかにしてやれば(わかる人にはわかることですが、この状態でsin波にtを渡すのはめちゃくちゃです)、
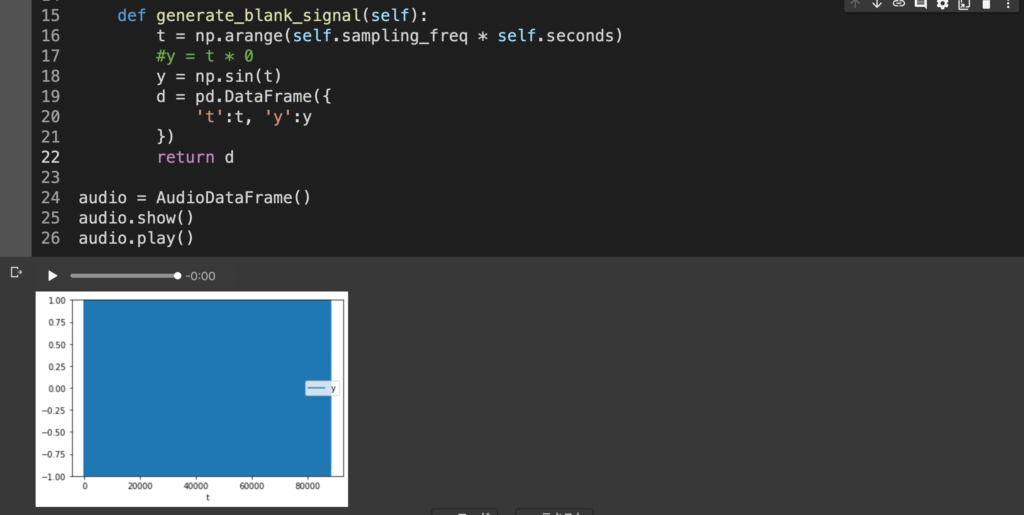
def generate_blank_signal(self):
t = np.arange(self.sampling_freq * self.seconds)
#y = t * 0
y = np.sin(t)
d = pd.DataFrame({
't':t, 'y':y
})
return d
とりあえず波形が生成され(グラフ上では細かすぎて潰れちゃってるけど)、再生ボタンを押すと非常に耳障りで嫌な、今すぐ鳴り止んでほしいレベルの高音が2秒ほど流れる。耳がぶっ壊れないように注意されたい。
メトロノームを実装してみる
今の状況では、何も考えずにインスタンスを立ち上げると2秒ほどの無音データが生成されたが、これは結局初期化のタイミングで__init__(self, bpm = 120, bars = 1, sampling_freq=44100)を指定しているので、BPM120で1小節(4拍)分の音声ファイルになっているわけだ。
さっきのようにビーーーとかシンセ的な音を作っていくのもいいんだけど、音楽!!!ということでやはりリズムを作ってみたくなってくる。ということでメトロノームを作って、インスタンスにadd_metronome()関数を当てるとマスターの音にメトロノームの音が追加されるものを考えてみることにする。とりあえず四分音符からはじめて8分、16分まで追加していくことにする。
面倒くさいので一旦self.audioをコピーしてから触って、最後に上書きすることにする。コピーしたついでに、メトロノームの情報は

def add_metronome(self):
audio = self.audio
audio['metronome'] = audio['t'] * 0
とりあえず4/4で1拍ずつしょうもない音が鳴るようにしたい。既に1拍あたり周波数ベースで何秒間あるかはself.secfreqperbeatで計算してあるので、この音声ファイルが始まった瞬間を1拍目と考えれば、i拍目の鳴るタイミングは secfreqperbeat * i の値になる。今回の音声に何拍含まれているかは self.beat に格納されているので、その回数だけループさせる。
→読み返していたら、secfreqperbeatにした上でもう一回掛け直していくのはやっぱ誤差が蓄積されていくからあんまり良くない気がしてきた。
def add_metronome(self, sub=True, subsub=True):
audio = self.audio
audio['metronome'] = audio['t'] * 0
for i in range(self.beats):
l = i * self.secfreqperbeat
audio.loc[ audio['t'] == np.round(l), 'metronome'] = 0.5
self.audio = audio
オーディオ上の時系列 t の該当箇所 secfreqperbeat * i の箇所だけメトロノームの値を適当に0.5にする。適当にやっているけどこれはスピーカーを傷めかねないので気をつけること(リミッティングしてるから最悪大丈夫だとは思うんだけど)。
メトロノームを作ったので、最終的な再生時に作成したメトロノームの音を追加するかどうかをplay時に選択できるようにしておくことにした。
def play(self, metronome=True, isLimit=True):
if metronome:
self.audio['y'] = self.audio['y'] + self.audio['metronome']
if isLimit:
self.audio.loc[ self.audio['y'] > 1, 'y' ] = 1
self.audio.loc[ self.audio['y'] < -1, 'y' ] = -1
display(Audio(self.audio['y'], rate=self.sampling_freq))
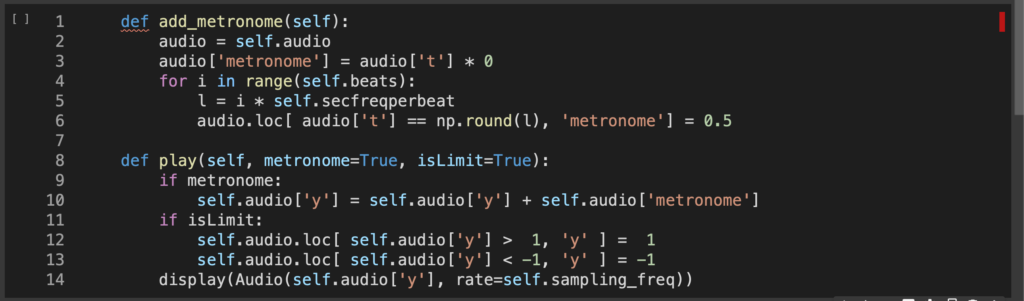
metronomeのデフォルト値はFalseにすればよかった。画像作り直すのが面倒なのでこのままで行く。
メトロノームの音を追加した状態でグラフを見たければ、add_metronome, playした後にshowすればいい。画像のコードはちょっと変だけど。
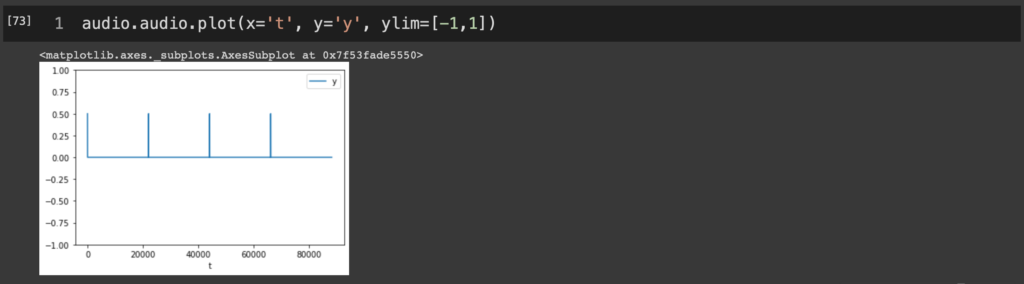
audio = AudioDataFrame()
audio.add_metronome()
audio.play(metronome=True)
audio.show()
続いて8分と16分も作っておく。ただし、毎回そんな細かい区切りまで鳴られても鬱陶しいので、そこはオプションで選択できるようにしておく。8分をsub=True、16分をsubsub=Trueで作成することにする。
各拍に対してその地点から self.secfreqperbeat / 2 の地点が裏なので8分に、
同様に各拍に対してその地点から self.secfreqperbeat / 4 ごとに打っていくと16分になる。
ということで、
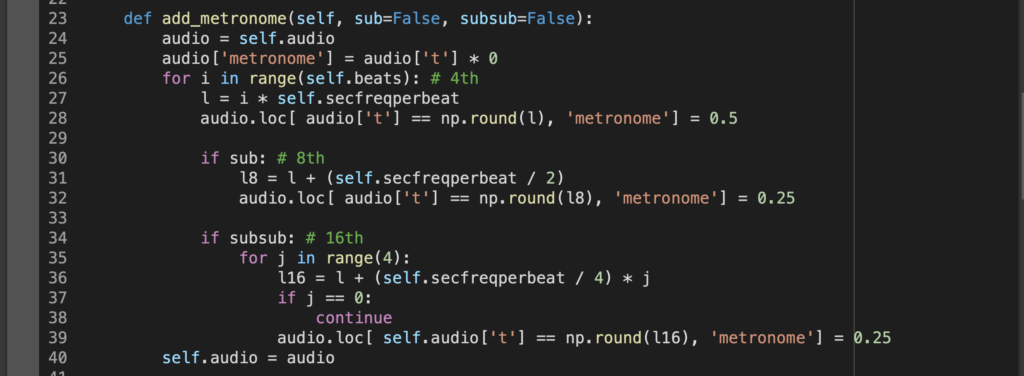
def add_metronome(self, sub=False, subsub=False):
audio = self.audio
audio['metronome'] = audio['t'] * 0
for i in range(self.beats): # 4th metronome
l = i * self.secfreqperbeat
audio.loc[ audio['t'] == np.round(l), 'metronome'] = 0.5
if sub: # 8th sub metronome
l8 = l + (self.secfreqperbeat / 2)
audio.loc[ audio['t'] == np.round(l8), 'metronome'] = 0.25
if subsub: # 16th sub metronome
for j in range(4):
l16 = l + (self.secfreqperbeat / 4) * j
audio.loc[ self.audio['t'] == np.round(l16), 'metronome'] = 0.25
self.audio = audio
四分音符の音よりは弱くていいので、今回は0.25とした。中身を見てみると、
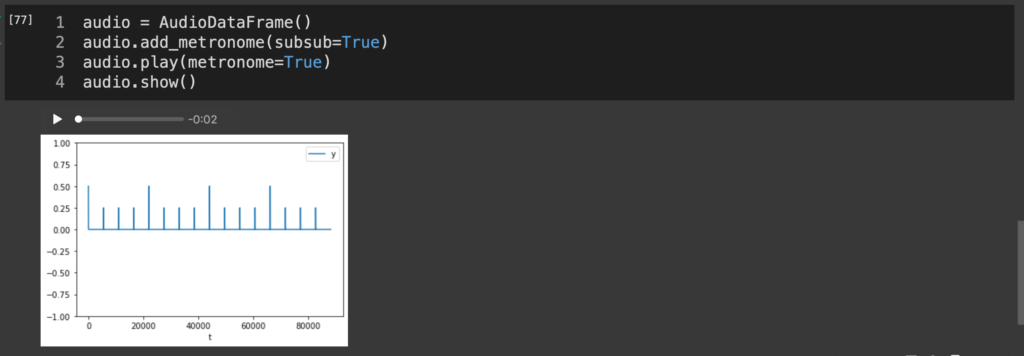
audio = AudioDataFrame()
audio.add_metronome(subsub=True)
audio.play(metronome=True)
audio.show()
タカカカタカカカタカカカタカカカって感じの音がなるはず。
最後に他の設定でも試しておく
AudioDataFrameのインスタンス立ち上げの時点でbpmやbarsの指定をしてあげれば他のパターンも試せる。自分のジャンル的に、bpm = 90のbars = 4でメトロノームのsub=Trueぐらいがいい感じになりそうな予感がする。
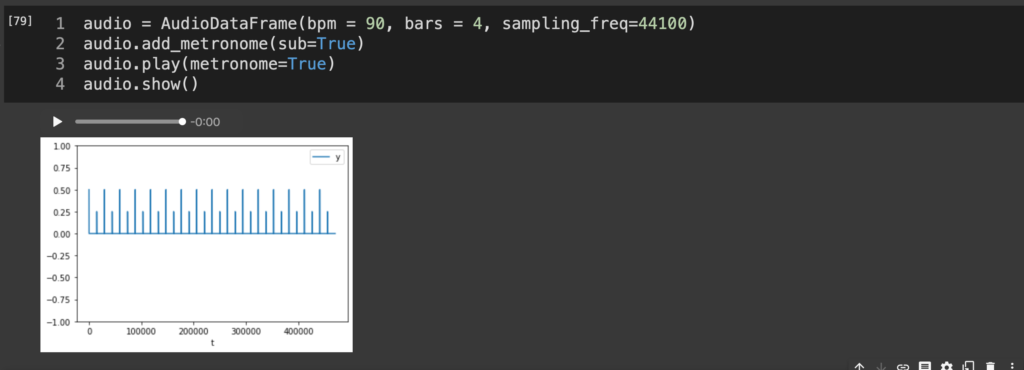
audio = AudioDataFrame(bpm = 90, bars = 4, sampling_freq=44100)
audio.add_metronome(sub=True)
audio.play(metronome=True)
audio.show()
今回はここまで。将来的にはこれ以外の音を鳴らしてみたり、あとは既存のオーディオファイルを合成してみる(既存のドラムキットからキックやスネアを読み出して、MIDI的に指定した位置に配置するようなこともできるようにしたい)。何より、今回はメトロノームとはいっても本当にしょうもないクリップ音みたいなのを定期的にパチッと鳴らしているだけの非常に嫌な構成なので、その辺りも改良していく。
今回の内容は以下にGistで貼っておきます。