

たまにしか使わないからいざ必要になったとき忘れそうになるんだけど、pandasは横方向の集計も実はかなり簡単にできる。
例によってサンプルデータを適当に生成
import numpy as np
import pandas as pd
np.random.seed(1)
N = 5
d = np.round(pd.DataFrame({
'id' : [i+1 for i in range(N)],
'val1': np.random.uniform(low=1, high=5, size=N),
'val2': np.random.uniform(low=1, high=5, size=N),
'val3': np.random.uniform(low=1, high=5, size=N)
}).set_index('id'), 2)
display(d)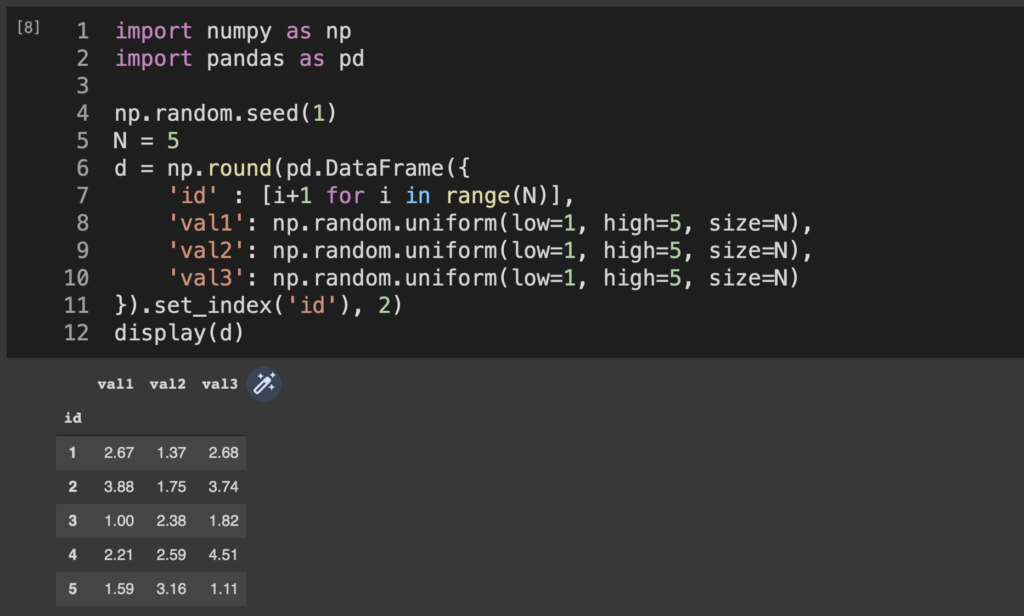
これを変数ごとに集計(var1, 2, 3それぞれの平均など)するとすれば、d.mean()なりd.describe()なりそのまま当てればよくて、
d.describe()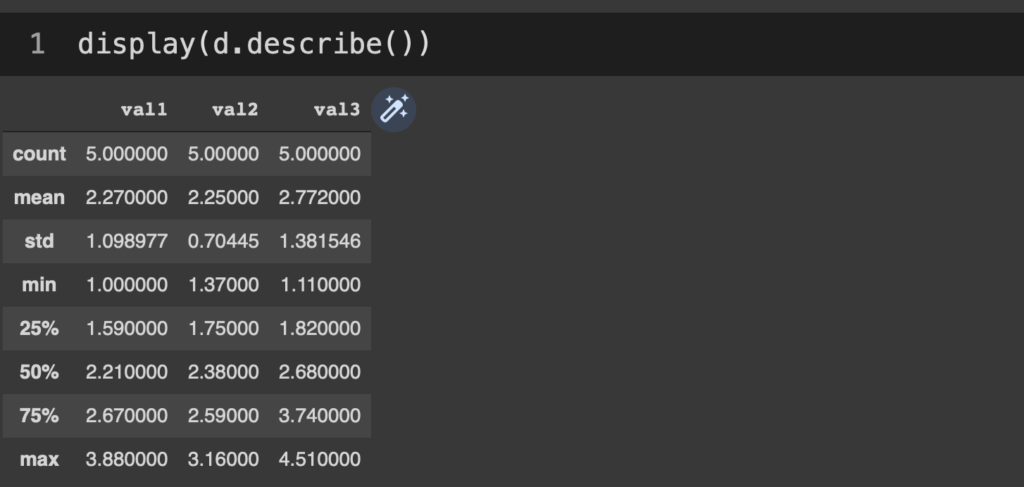
じゃあここで横方向の平均(インスタンスごとに3変数の平均)を出すにはどうすればいいかと考えたときには、もちろんそのまま
d['mean'] = 0
for v in ['val1', 'val2', 'val3']:
d['mean'] += d[v]
d['mean'] = d['mean'] / 3
display(d)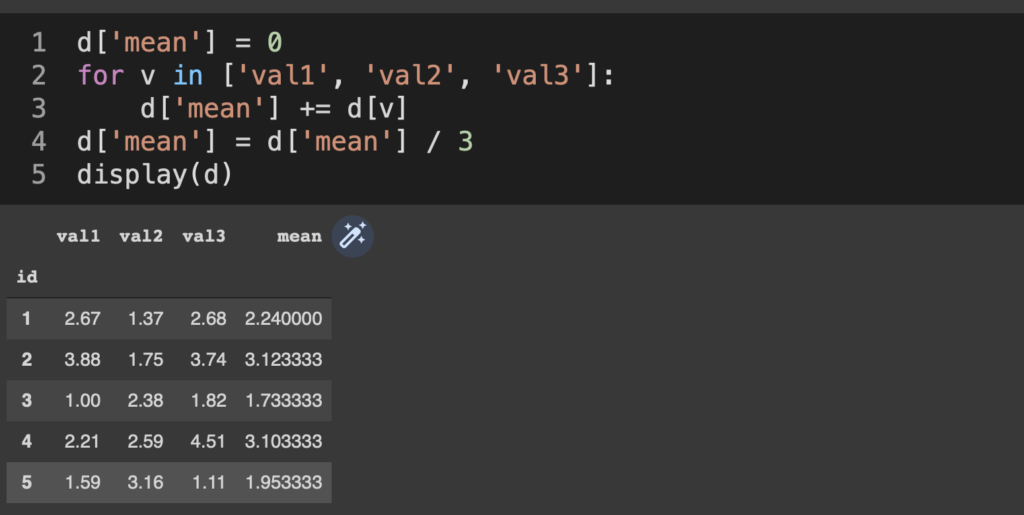
とかやることもできる。あるいはバグ覚悟でデータフレームごと転置してからmeanかけることもまあできなくはない。ないが、数が増えてくるとやってられないわけです。pandasのdocumentationを見るとmean()にはpandasお馴染みのaxisを引数に取ることができる。つまり、ここをaxis=1にすることで横方向の集計ができる。

axisパラメータにデフォルトはないって書いてあるけど、省略すると縦方向に集計されているのは明白ですね。
ということでaxis=1で集計すると、
d.mean(axis=1)
これはpandas.Series形式で返ってきている。つまり、2重ブラケットを使って変数を抽出した上でmean()をかければ、
d['mean1+2'] = d[['val1', 'val2']].mean(axis = 1)
d['mean_all'] = d[['val1', 'val2', 'val3']].mean(axis = 1)
display(d)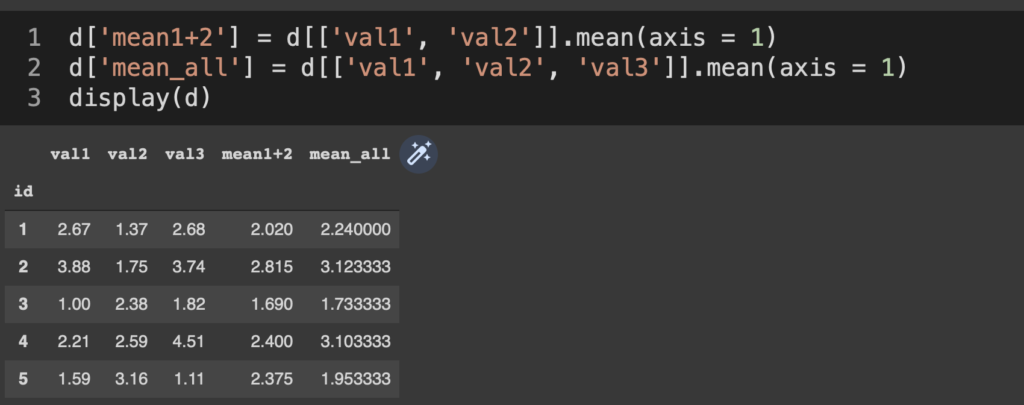
必要な変数だけを使った横方向の集計をして元データに追加することなんかもできる。これは当然meanだけじゃなくvarあたりでも動く。
念のため書いておくと、d[‘変数名’] に集計結果を当てる場合、左右のデータフレーム(厳密には代入する値としての右側はSeriesだけど)でインデックスの値が一致している必要がある(この場合なら同じid同士で代入される)。その辺はpandasのjoin()でのindex重複時の挙動についての検証で少し調べています。