


ChatGPT等の登場で大学では「学生がレポートに使ったら…」などの心配をしている人が多くいるが、正直なところそんなことは全くもってどうだっていい。教育機会は提供しているし、そこにコミットするかどうかは勝手にすればいい。不正による不公平という点でいえば、他の履修者と一緒に課題を進めるとか、一部の学生だけが過去問を手に入れただとか、対処すべきことは遥かに多い。それらの問題から目を背けていながらChatGPTだけに文句をつけることはおそらく無理だろう。そんな暇があるなら、自分がこれらの最新ツールをどう活かせるかの思考とトライアルを続けた方がいい。
個人的にChatGPTをどう活用していくかはかなり方向性が見えてきた。だがここではそれとは全く別の話として、以下にGPTモデルとのクソのやりとりを残しておく。
—
Colabでやりとりしている前半はOpenAIのDaVinci(GPT3.5)のCompletion APIとのやり取り。非常に簡単にやったaskの実装は初回(OpenAIのAPIで遊ぶ(1):Pythonで言葉を投げかける篇)参照。
「マーケティング研究でRFMモデルを用いた代表的な論文を挙げてください」

いいか。そんな論文はない。そんなジャーナルもないしそんな研究者もいない。
「マーケティング研究でRFMモデルを用いた 実 在 す る 代表的な論文を挙げてください」

専門知識のない人間が下手に使おうとすると、この辺りから急激に使いこなすのに苦労するようになる。
下手に指示したことで虚実入り混じった回答が返ってくるようになる。とはいえ、こいつはつまるところ言語モデルなので、彼が(ここで「彼が」と書いているのはこの言語モデルはDaVinciと命名されているためでありそれ以上の意図はない)返す言葉はあながち『嘘』とは言い切れない。彼が学んでいるのはいつだって「ある言葉に対してどう返せば最もそれらしい返答になるか」という“様式”であり、その内面にあらゆる論文から知識が一般化された小宇宙が存在しているわけではない。論文を挙げろと言われてそれっぽい名前とタイトルとジャーナルをでっち上げて回答している、その意味で彼のやっていることは至極正しい行為なのである。
本家ChatGPTではどうかといえば、

嘘ついてんじゃねえよ。
RFMとかCLVとかやってる人間なら一瞬で気づくことだが、1つ目に挙げられている文献”RFM and CLV: Using ISO~”は明かにFader, Hardie & Lee (2005) “RFM and CLV: Using iso-value curves for customer base analysis”に引っ張られている。ジャーナル”Journal of Targeting, Measurement and Analysis for Marketing”自体は実在する。というかさっきも述べた通り、この手のものは中途半端に実在するからこそ真偽の判定がしづらく厄介なのだ。

実在するらしい。
ただ、いずれにせよ(仮にこれが実在したとしても)「代表的な論文」として挙げるべきものとは思えない。もう許さん。

ここではっきりした。
1つ目の論文のDOIとして挙げられている10.1057~はCapizzi, M., Ferguson, R., & Cuthbertson, R. (2003). Loyalty trends for the 21st century. Journal of Targeting, Measurement and Analysis for Marketing, 12(3), 199-212.である。ある論文が査読前のアーリーアクセスで公開されていたものが同じDOIで査読後にタイトルが変更されることはごく稀にあるが、さすがに著者名まで丸ごと変わるとは考えにくい。ちなみに2つ目もジャーナルは同じだが中身は全く異なる論文だった。Hsiaoがそんな総論みたいな論文書いてたらとっくに読んで自分の論文上で引用しまくってるだろうな。
誰かが「ChatGPTで無限にそれらしい陰謀論を作成してネットに流したらどうなるかな」なんて言ってたけど、(個人的にはまあまあ面白そうだと思うが)実際のところ大変なことになると思う。陰謀論もそうだけど、インパクトの強い嘘を流すのは簡単、その真偽を検証し訂正し認識を広めるには大変な労力がかかる。
つまるところ、今の彼にデータベースを探索させるようなタスクは与えるべきではない。どちらかというと、与えた文章の情報量を減らすようなタスク、つまるところ要約でもさせた方がいい。たとえば、

悪くない。日本語でもやってもらおう。
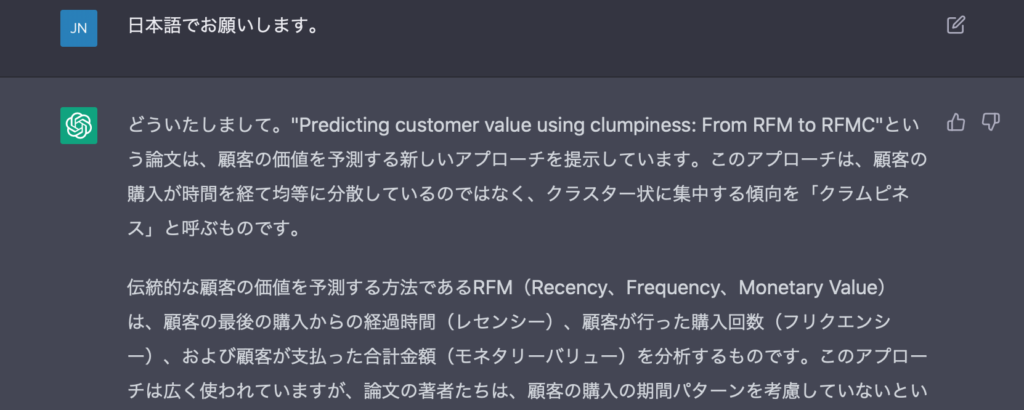
ちなみに要約するにしても、たとえば Platzer, M., & Reutterer, T. (2016). Ticking away the moments: Timing regularity helps to better predict customer activity. Marketing Science, 35(5), 779-799. を要約させた上で追加の質問をしてみると、

こんな風に返ってくる、しかし、残念ながらこの論文の中ではこの2つの関係性はそれなりに明確に論じられている。そして何より気に入らないのは最後の1段落。ChatGPTはいつも「もっと詳しくは他の論文やデータを見ろ」なんて常套句のように返してくるけど、ここの”but this would depend on the specific context”はそれなりに主観たりうる言葉ではないだろうか。この論文の中身についてディスカッションしてるはずなのに、「確かにregularityの度合いと過去の購買は関係するかもしれないけど、それって特定の文脈とかデータに依存するんじゃない?」って勝手なこと言ってて、そんな当たり前のこと言ったら議論なんかできないんだよ。データや文脈に依存するのは当たり前で、そこからいかに一般化するかだし、何よりそもそもお前はこの論文の中でその記述を見つけられてないんだよ。議論のパートナーになりうるツールがそういう論点ずらしみたいな議論の仕方をしてこないでくれ。
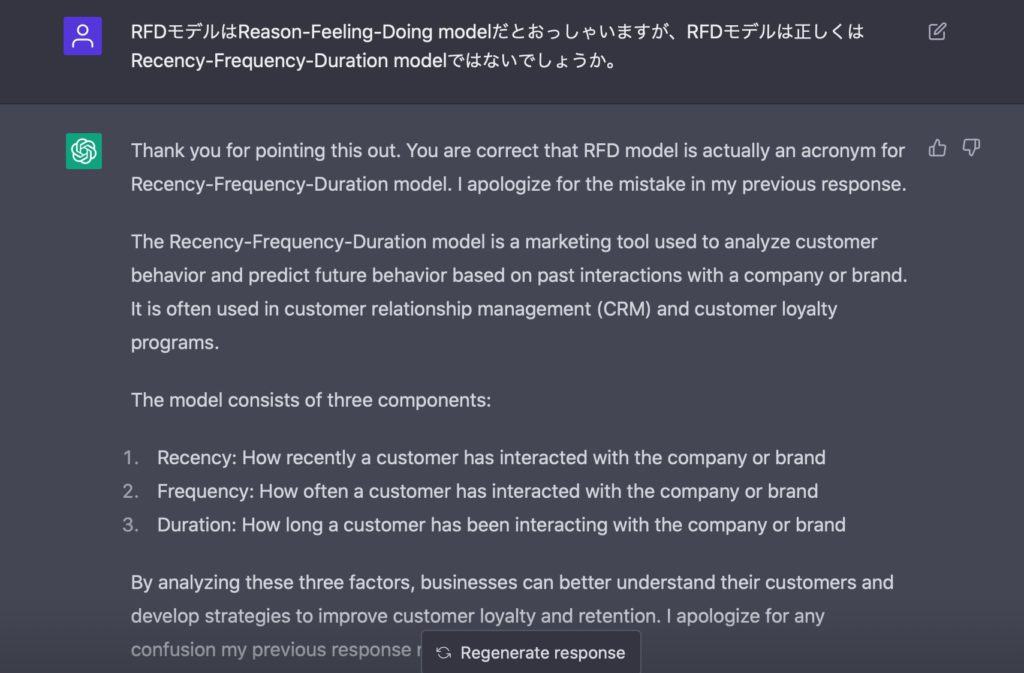
あとはねー、Wang, C., Zhou, R., & Lee, M. K. (2021). Can loyalty be pursued and achieved? An extended RFD model to understand and predict user loyalty to mobile apps.で、

RFDはそんなモデルじゃないですねー。本文中にも”the RFD (recency, frequency, duration) model shows its usability and effectiveness and has been widely used”って書かれてますよ。
勘違いしないでほしいけど、僕は自分の専門周りの論文を読むことに関しては全く苦にならないので、これ使って論文レビューを横着しようとかそういうつもりはない。自分の理解を深めるにあたり、同じ内容を異なる切り口から複数回入力して自分の認識と照らし合わせることは意外と重要なのだ。決してAIの揚げ足取りではない。
現にこれもディスカッションで解決できる。
楽しい。